
while (1): study();
NLG 지표 간단 정리 본문
1. BLEU (bilingual evaluation understudy)
n-gram precision, 생성한 문장을 기준으로 reference의 유사도를 파악.
BLEU (bilingual evaluation understudy) is an algorithm for evaluating the quality of text which has been machine-translated from one natural language to another. Quality is considered to be the correspondence between a machine's output and that of a human: "the closer a machine translation is to a professional human translation, the better it is" – this is the central idea behind BLEU.[1] BLEU was one of the first metrics to claim a high correlation with human judgements of quality,[2][3] and remains one of the most popular automated and inexpensive metrics.
Scores are calculated for individual translated segments—generally sentences—by comparing them with a set of good quality reference translations. Those scores are then averaged over the whole corpus to reach an estimate of the translation's overall quality. Intelligibility or grammatical correctness are not taken into account.[citation needed]
BLEU's output is always a number between 0 and 1. This value indicates how similar the candidate text is to the reference texts, with values closer to 1 representing more similar texts. Few human translations will attain a score of 1, since this would indicate that the candidate is identical to one of the reference translations. For this reason, it is not necessary to attain a score of 1. Because there are more opportunities to match, adding additional reference translations will increase the BLEU score.[4]
BLEU - Wikipedia
From Wikipedia, the free encyclopedia Jump to navigation Jump to search Algorithm for evaluating the quality of machine-translated text This article is about the evaluation metric for machine translation. For other uses, see Bleu (disambiguation). BLEU (bi
en.wikipedia.org
2. ROGUE
n-gram recall, 마찬가지로 유사도를 따지지만 reference가 기준이라는 게 다름.
ROUGE, or Recall-Oriented Understudy for Gisting Evaluation,[1] is a set of metrics and a software package used for evaluating automatic summarization and machine translation software in natural language processing. The metrics compare an automatically produced summary or translation against a reference or a set of references (human-produced) summary or translation.
Natural language processing - Wikipedia
From Wikipedia, the free encyclopedia Jump to navigation Jump to search This article is about natural language processing done by computers. For the natural language processing done by the human brain, see Language processing in the brain. Field of compute
en.wikipedia.org
3. METEOR
precision과 recall을 동시에 고려한 지표
METEOR (Metric for Evaluation of Translation with Explicit ORdering) is a metric for the evaluation of machine translation output. The metric is based on the harmonic mean of unigram precision and recall, with recall weighted higher than precision. It also has several features that are not found in other metrics, such as stemming and synonymy matching, along with the standard exact word matching. The metric was designed to fix some of the problems found in the more popular BLEU metric, and also produce good correlation with human judgement at the sentence or segment level. This differs from the BLEU metric in that BLEU seeks correlation at the corpus level.
4. NIST
BLEU의 개선된 버전. 빈도가 낮은 n-gram일수록 weight를 높게 줌. 즉, rare pattern을 생성하는 것에 더 높은 점수를 부여.
NIST is a method for evaluating the quality of text which has been translated using machine translation. Its name comes from the US National Institute of Standards and Technology.
It is based on the BLEU metric, but with some alterations. Where BLEU simply calculates n-gram precision adding equal weight to each one, NIST also calculates how informative a particular n-gram is. That is to say when a correct n-gram is found, the rarer that n-gram is, the more weight it will be given.[1]
5. CIDEr
precision, recall, grammatical correctness 등을 모두 내재적으로 파악할 수 있다고 함. human evaluation과 agreement가 높다고 함.
CIDEr (Consensus-based Image Description Evaluation). Our metric measures the similarity of a generated sentence against a set of ground truth sentences written by humans. Our metric shows high agreement with consensus as assessed by humans. Using sentence similarity, the notions of grammaticality, saliency, importance and accuracy (precision and recall) are inherently captured by our metric.
* ref: [CIDEr: Consensus-based Image Description Evaluation]
6. PARENT
링크: https://arxiv.org/abs/1906.01081
data-to-text에서 reference divergence(reference 내 table에 없는 정보 OR table에 있는 유용한 정보가 reference에 없음)로 인해 BLEU, ROGUE가 비효율적이기 때문에 고안된 metric. precision은 reference와 table의 합집합을 이용하여 계산하기 때문에 정보가 reference에 없는 경우에 대처할 수 있고, recall은 교집합을 이용하여 table에 없는 정보가 reference에 있는 경우에 대처할 수 있다.
recall은 특이하게 다음과 같은데
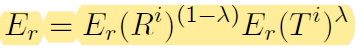
lambda를 이용하여 reference에 더 집중할 지, table에 더 집중할 지 비율을 달리할 수 있다. 1-lambda가 1에 가까울수록 referene에 집중하는데, 이는 데이터에 따라 최적값이 다르므로 tuning이 필요하다.
생성된 n-gram 토큰이 table에 나올 확률을 계산하는 Word Overlap Model(PARENT-W)와 테이블에 생성된 n-gram 토큰이 수반될 확률을, 테이블의 각 어휘에 n-gram 토큰이 수반될 확률을 최대화하는 것으로 계산하는 Co-occurence Model이 있다.
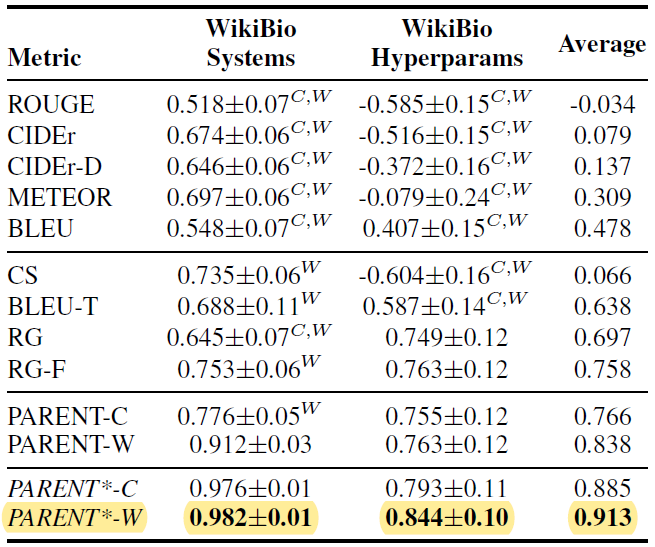
일반적으로 1-4 gram을 평균낸다고 하며, 정성평가 결과와 높은 수준의 상관관계를 보인다.
'학습 > 딥러닝' 카테고리의 다른 글
| [PyTorch] Contiguous Tensor (0) | 2021.09.29 |
|---|
