
while (1): study();
Ch5. 오차역전파법 본문
* 책 내용 요약이 아니니 유의하시기 바랍니다.
오차역전파에 대해서 이전에 해석 강의를 들은 적이 있긴 했는데, 솔직히 감이 잘 안 왔습니다. 이 책을 보고 나서야 비로소 '아! 이런거구나!'라고 제대로 와닿는 느낌이었습니다. 여러모로 읽으면 읽을수록 '읽기를 잘했다'라고 생각이 드는 책이네요. 이 책에서는 계산 그래프를 통해서 오차역전파에 대해 설명하고 있습니다. CS231n에서 설명한 방식을 차용했다고 하는데, 역시 인공지능 배우는 사람이라면 다 한번 거쳐야 하는 관문인걸까.. 싶습니다. 시간 날 때 꼭 봐야겠네요.
계산 그래프로 푸는 방법의 이점은 2가지입니다.
1. 국소적 계산: 단순한 계산에 집중하여 문제를 단순화
2. 중간 계산 결과 보관
3. 미분을 효율적으로 계산
기존 수치 미분 방법을 이용한 경사 하강법은 시간이 정말 오래 걸렸습니다. 음, 넘파이의 nditer 메서드를 사용했을 때 단순히 모든 원소에 대해 반복문을 돌리는 것보다 빠른 것 같기는 하지만, 그래도 역시 역전파 학습법에 비하면 느린 것은 사실이죠.
오차역전파의 핵심은 '중간 계산 결과를 보관한다는 것'입니다. 즉 일종의 DP문제로 학습에 접근한다고 볼 수 있죠. 예를 들어 곱셈의 역전파는 다음과 같이 계산됩니다.

이러한 결과는 그냥 나온 것이 아니라 $z = xy$라고 두었을 때 $dy = x$이고 $dx = y$인 것을 바탕으로 연쇄법칙에 의해 각 가중치의 미분 연산을 단순화한 것이라고 볼 수 있습니다. 즉, 곱셈노드는 입력으로 받은 x와 y에 대해 저장하고 있다가, 역전파 시 서로 위치를 바꿔 입력으로 들어오는 미분에 곱해주면 됩니다.
덧셈은 더 간단합니다.
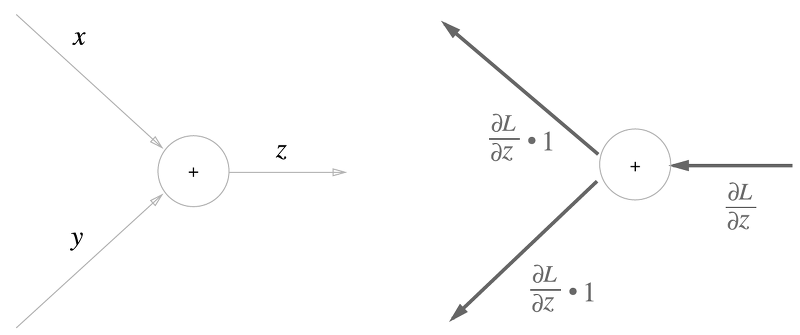
$z = x + y$일 때 x, y 각각에 대한 편미분이 1이므로, 역전파 시 입력을 그대로 뒤로 보내주면 됩니다. 이런식으로 역전파를 사용하면 복잡한 계산을 단순화하여 학습을 효율적으로 진행할 수 있습니다.
실제 신경망에 사용되는 계층이 역전파는 사진을 올려놓겠습니다만, 자세한 도출 과정은 생략하겠습니다.
1) 시그모이드

2) Affine 계층

3) 소프트맥스 (with Cross Entropy)

신기한 것은 교차 엔트로피 손실을 사용했을 때 소프트맥스 층의 역전파가 간결하게 $y-t$가 되어버린다는 점입니다. 이는 의도적으로 이렇게 설계된 것이라고 합니다. 또한 MSE를 손실함수로 사용하고 항등함수를 출력층으로 놓아도 똑같이 역전파가 $y-t$가 된다고 합니다. 정말 신기합니다..
역전파를 바탕으로 구현한 계층들을 이용하여 신경망을 학습하면, 수치 미분을 사용할 때보다 월등히 빨라지는 것을 알 수 있습니다. 또한 우리는 수치 미분을 사용하여 역전파 알고리즘이 얼마나 잘 구축되었나 확인할 수 있습니다. 이를 기울기 확인(gradient check)라고 한다고 합니다.
다만 저 같은 경우 책에서 나온 오차보다 실제 오차가 매우 크게 나왔습니다. 이것 때문에 뭐가 잘못되었는지 밤새 살펴보았는데... 도저히 오차가 좁혀지지를 않네요. 실제 오차역전파를 이용하여 학습은 잘 진행됩니다.

다만 수치 미분 기울기와 역전파 기울기가 다음과 같이 차이가 납니다.

두 번째 레이어의 편향은 거의 0.1 정도 차이가 나고 있는데 이 정도면 충분히 학습에 큰 영향을 줄 수 있는 수치라고 생각합니다.. 원인은 두 가지 정도 생각하고 있습니다.
1. 수치 미분 알고리즘 구축에서 문제가 있었다.
2. 정밀도의 차이이다.
첫 번째 케이스의 경우 소스코드까지 살펴보았는데 문제가 없었고.. (단일 샘플에 대한 수치 미분도 책의 샘플과 동일하게 반환됩니다) 정밀도 같은 경우 넘파이의 부동소수점 배열 기본 정밀도가 64비트인 것 같은 데다가, 문제가 될 것 같으면 이전 시그모이드 구현 때처럼 애초에 float64로 형변환을 시키고 들어가기 때문에.. 어디서 문제가 발생했는지 찾으려면 좀 걸릴 것 같습니다.
해법을 찾았습니다. 힘들었네요.. 우선 수치미분으로 구했을 경우와 역전파로 구했을 때의 기울기를 실제로 살펴보았습니다.

보니까 수치 미분으로 구한 기울기가 아예 전부 0입니다. 즉, 훈련이 전혀 안 됐다고 판단했습니다. 그럼 어디가 문제일까요? 우선 알고리즘부터 확인해봤습니다. 다음은 기존의 모델에서 그라디언트를 구하는 함수입니다.
def get_grad(self, x, y)
loss_W = lambda W: self.get_loss(x, y)
grads = {}
grads['W1'] = numerical_gradient(loss_W, (self.params['W1']))
grads['b1'] = numerical_gradient(loss_W, (self.params['b1']))
grads['W2'] = numerical_gradient(loss_W, (self.params['W2']))
grads['b2'] = numerical_gradient(loss_W, (self.params['b2']))
return grads
numerical gradient 함수는 함수와 입력을 받아, 중앙 차분하여 기울기를 구합니다. 다만 인자로 준 함수의 인자(말이 좀 복잡하네요)가 더미 인자라는 점에서 조금 의구심이 들었습니다. 가중치가 매번 변하면서 $f(x + h)$와 $f(x - h)$의 차이를 구해야 하는데 매번 가중치 업데이트가 안 되고 있는 것은 아닐까 싶어서요. 혹시 책이 틀릴 가능성도 있으니까, 조금 코드를 직관적으로 바꿔봤습니다.
다음 함수는 모델의 가중치를 업데이트해서 미분한 뒤, 다시 원래 가중치로 되돌리는 작업을 명시적으로 보여줍니다.
def get_grad(self, x, y):
def loss_W(model, weight, key) :
origin_params = self.params[key]
model.params[key] = weight
loss = model.get_loss(x, y)
model.params[key] = origin_params
return loss
grads = {}
grads['W1'] = numerical_gradient(loss_W, (self, self.params['W1'], 'W1'))
grads['b1'] = numerical_gradient(loss_W, (self, self.params['b1'], 'b1'))
grads['W2'] = numerical_gradient(loss_W, (self, self.params['W2'], 'W2'))
grads['b2'] = numerical_gradient(loss_W, (self, self.params['b2'], 'b2'))
return grads물론 결과는 같았습니다.. 삽질이었네요. 생각해보니 loss_W 함수 안에서 호출하는 get_loss 메서드는 추론 과정에서 알아서 가중치를 클래스 프로퍼티로 업데이트합니다.
알고리즘이 문제가 아니라면 정밀도가 문제일까요? 기존 수치 미분 함수를 살펴보았습니다.
def numerical_gradient(f, x, h=1e-4):
x = x.astype('float64')
grad = np.zeros_like(x)
# generate iterator
iter = np.nditer(x, flags=['multi_index'], op_flags=['readwrite'])
while not iter.finished:
idx = iter.multi_index
tmp_val = x[idx]
# central diff
x[idx] = tmp_val + h
fx_h1 = f(x)
x[idx] = tmp_val - h
fx_h2 = f(x)
grad[idx] = (fx_h1 - fx_h2) / (2. * h)
x[idx] = tmp_val
iter.iternext()
return grad넘파이 nditer 메서드를 사용하면 효과적으로 배열을 순회할 수 있습니다. 제가 알기로 넘파이 소수의 기본 정밀도는 float64입니다. 따라서 처음부터 입력으로 받았던 x를 float64로 형변환을 시켜서 더 정밀한 결과를 내놓고 싶었습니다. 코드를 가만히 살펴보다가 문득 드는 생각, '형변환을 하지 말아볼까?'이었습니다.
아래 코드는 단순히 float64로 바꾸는 라인만 지웠습니다.
def numerical_gradient(f, x, h=1e-4):
grad = np.zeros_like(x)
# generate iterator
iter = np.nditer(x, flags=['multi_index'], op_flags=['readwrite'])
while not iter.finished:
idx = iter.multi_index
tmp_val = x[idx]
# central diff
x[idx] = tmp_val + h
fx_h1 = f(x)
x[idx] = tmp_val - h
fx_h2 = f(x)
grad[idx] = (fx_h1 - fx_h2) / (2. * h)
x[idx] = tmp_val
iter.iternext()
return grad결과는 성공적이었습니다. 다시 한번 기울기를 직접 보겠습니다.

밑의 두 줄이 두 번째 레이어의 편향의 기울기입니다만, 두 그래디언트가 상당히 유사하게 도출되었음을 알 수 있습니다. 가중치 간 절대값 오차도 매우 작아졌음이 한 눈에 보입니다.

중요한 것은 '왜 형변환을 안했더니 제대로 된 결과가 나오는가?'입니다. 저번에 수치 미분을 구현할 때 정수 배열에 인덱싱을 하면 소수점 뒷자리가 날라가버리는 현상이 발생했었습니다. 이번에는 그것과는 또 다른 문제인 듯 합니다. 사실 형변환을 하던말던 이전의 값과 이후의 값, 그리고 이전의 타입과 이후의 타입이 완전히 같은 것을 확인했습니다. 뭔가 이론 이상의 내용이 있는 것 같긴한데..
더 중요한 것은 '함부로 형변환 막해서 끼워맞추기 식으로 코딩하면 안된다는 것'이겠죠... 생각해보니 Weight tying을 이용한 컴팩트한 번역기를 만들어보겠다고 덤벼놓고 추론 과정에서 막혔었는데, 이게 원인인 것 같네요 아무래도..
왜 이런 현상이 발생하는지 아시는 분은 댓글 부탁드립니다..
'독서' 카테고리의 다른 글
| Ch7. 합성곱 신경망 (0) | 2021.07.22 |
|---|---|
| Ch6. 학습 관련 기술들 (0) | 2021.07.21 |
| Ch4. 신경망 학습 (0) | 2021.07.18 |
| Ch3. 신경망 (0) | 2021.07.18 |
| Ch2. 퍼셉트론 (0) | 2021.07.18 |



