
while (1): study();
Ch4. Word2Vec 속도 개선 본문
이 장에서는 이전 장에서 구현했던 Word2Vec의 속도를 개선해봅니다. 두 가지 측면에서 개선점이 있습니다.
1. Embedding layer를 이용한 입력층 연산 감소
2. Negative sampling을 이용한 출력층 연산 감소
추가적으로 단어의 밀집 벡터를 통계 기반 방법으로 얻은 경우 Distributional representation이라고 표현하며, 추론 기반 방법으로 얻은 경우 Distributed representation이라고 표현합니다. 따라서 우리는 결론적으로 최적의 Distributed representation을 얻는 것이 목표입니다.
1. Embedding layer
이전의 CBOW는 입력 가중치가 (Vocab size, Hidden size)였습니다. 입력으로 주어지는 맥락은 한정적이므로 대부분의 가중치는 사용되지 않게 되는데, 따라서 불필요한 연산이 너무 많아집니다. 임베딩 레이어는 가중치에서 연산에 필요한 행만 쏙쏙 빼오는 역할을 합니다.
class Embedding:
def __init__(self, W):
self.params = [W]
self.grads = [np.zeros_like(W)]
self.idx = None
def forward(self, idx):
W, = self.params
self.idx = idx
out = W[idx]
return out
def backward(self, dout):
dW, = self.grads
dW[...] = 0
np.add.at(dW, self.idx, dout)
return None
2. Negative Sampling
마찬가지로 출력층에서도 정답 단어의 개수는 한개임에도 불구하고, 출력 가중치 모두에 대해서 연산하게 되므로 불필요한 연산이 너무 많습니다. 따라서 다중분류를 이중 분류로 바꾸기 위해 Negative Sampling을 도입합니다.
Negative Sampling은 우선 '이 맥락에서 출력될 단어는 무엇인가요?'라는 문제를 '이 맥락에서 출력될 단어는 이것인가요?'로 바꿉니다. 따라서 우리는 해당 단어가 정답일 확률을 시그모이드 함수를 사용하여 도출하게 됩니다. 어차피 관건은 하나의 정답 단어를 맞추는 것이기 때문에 이런 방법론이 유효하게 되는 것이죠.
이 과정에서 정답 단어의 ID를 임베딩하여 중간 출력 h와 내적하게 됩니다. 일련의 과정을 압축하기 위해서 이를 하나의 계층으로 구현합니다.
class EmbeddingDot:
def __init__(self, W):
self.embed = Embedding(W)
self.params = self.embed.params
self.grads = self.embed.grads
self.cache = None
def forward(self, h, idx):
target_W = self.embed.forward(idx)
out = np.sum(target_W * h, axis=1)
self.cache = (h, target_W)
return out
def backward(self, dout):
h, target_W = self.cache
dout = dout.reshape(dout.shape[0], 1)
dtarget_W = dout * h
self.embed.backward(dtarget_W)
dh = dout * target_W
return dh다만 아직 문제가 있습니다. 손실을 구할 때 해당 단어가 정답일 확률만 도출하여 학습하게 되면, 오직 "정답일 확률"만 업데이트되고, 나머지 정답이 아닌 경우들에 대해서는 가중치 업데이트가 이뤄지지 않습니다. 모든 오답들에 대해서 다시 손실을 구하려면 결국 모든 $W_{OUT}$ 가중치에 대해 연산하는 것과 마찬가지인 격입니다. 따라서 우리는 몇 개의 오답 케이스를 샘플링하여 이것에 대한 손실을 구합니다. 이것이 바로 네거티브 샘플링입니다.
샘플링은 코퍼스 내의 단어 출현 빈도에 기반합니다. 조금 더 의미있는 오답들의 가중치를 많이 갱신시키기 위해 상대적으로 빈도가 높은 단어들을 더 많이 뽑겠다는 것입니다. 단, 빈도가 낮은 단어들에 대해서 완전히 버리지 않기 위해서 확률에 1 이하의 어떤 수를 제곱하여 사용합니다. 따라서 네거티브 샘플링의 샘플링 확률은 다음과 같은 수식을 따릅니다.
$$P`(w_{i}) = {P(w_{i})^{0.75} \over \sum_{j}^{n}P(w_{i})^{0.75}}$$
따라서 다음과 같이 구현할 수 있습니다.
class UnigramSampler:
def __init__(self, corpus, power, sample_size):
self.sample_size = sample_size
self.vocab_size = None
self.word_p = None
counts = Counter()
for word_id in corpus:
counts[word_id] += 1
vocab_size = len(counts)
self.vocab_size = vocab_size
self.word_p = np.zeros(vocab_size)
for i in range(vocab_size):
self.word_p[i] = counts[i]
self.word_p = np.power(self.word_p, power)
self.word_p /= np.sum(self.word_p)
def get_negative_sample(self, target):
batch_size = target.shape[0]
negative_sample = np.zeros((batch_size, self.sample_size), dtype=np.int32)
for i in range(batch_size):
p = self.word_p.copy()
target_idx = target[i]
p[target_idx] = 0
p /= p.sum()
negative_sample[i, :] = np.random.choice(self.vocab_size, size=self.sample_size, replace=False, p=p)
return negative_sample이떄의 손실은 정답 케이스에 대한 손실과, 모든 오답 케이스들에 대한 손실을 도하여 구합니다.
class NegativeSamplingLoss:
def __init__(self, W, corpus, power=0.75, sample_size=5):
self.sample_size = sample_size
self.sampler = UnigramSampler(corpus, power, sample_size)
self.loss_layers = [SigmoidWithLoss() for _ in range(sample_size + 1)]
self.embed_dot_layers = [EmbeddingDot(W) for _ in range(sample_size + 1)]
self.params, self.grads = [], []
for layer in self.embed_dot_layers:
self.params += layer.params
self.grads += layer.grads
def forward(self, h, target):
batch_size = target.shape[0]
negative_sample = self.sampler.get_negative_sample(target)
score = self.embed_dot_layers[0].forward(h, target)
correct_label = np.ones(batch_size, dtype=np.int32)
loss = self.loss_layers[0].forward(score, correct_label)
negative_label = np.zeros(batch_size, dtype=np.int32)
for i in range(self.sample_size):
negative_target = negative_sample[:, i]
score = self.embed_dot_layers[1 + i].forward(h, negative_target)
loss += self.loss_layers[1 + i].forward(score, negative_label)
return loss
def backward(self, dout=1):
dh = 0
for l0, l1 in zip(self.loss_layers, self.embed_dot_layers):
dscore = l0.backward(dout)
dh += l1.backward(dscore)
return dh
지금까지 구현한 것들을 이용하여 개선된 버전의 CBOW를 구현해볼 수 있습니다.
class CBOW:
def __init__(self, vocab_size, hidden_size, window_size, corpus):
V, H = vocab_size, hidden_size
W_in = 0.01 * np.random.randn(V, H).astype('f')
W_out = 0.01 * np.random.randn(V, H).astype('f')
self.in_layers = []
for i in range(2 * window_size):
layer = Embedding(W_in)
self.in_layers.append(layer)
self.ns_loss = NegativeSamplingLoss(W_out, corpus, power=0.75, sample_size=5)
layers = self.in_layers + [self.ns_loss]
self.params, self.grads = [], []
for layer in layers:
self.params += layer.params
self.grads += layer.grads
self.word_vecs = W_in
def forward(self, contexts, target):
h = 0
for i, layer in enumerate(self.in_layers):
h += layer.forward(contexts[:, i])
h *= 1 / len(self.in_layers)
loss = self.ns_loss.forward(h, target)
return loss
def backward(self, dout=1):
dout = self.ns_loss.backward(dout)
dout *= 1 / len(self.in_layers)
for layer in self.in_layers:
layer.backward(dout)
return None실제로 CBOW를 이용한 학습의 결과입니다. PTB 데이터셋이 그렇게 샘플이 많은 것은 아니지만, 실험의 편의성을 위해서 1000개의 샘플만 잘라내어 학습시켜 보았습니다.

네거티브 샘플링이 모든 오답에 대해 가중치를 갱신하는 것이 아니기 때문에 상대적으로 학습이 불안정합니다. 그럼에도 불구하고 손실이 하강하는 방향으로 학습이 진행되고 있습니다. 다만 조금 걸리는 점은 기울기가 점점 커지고 있다는 점인데, 이유는 잘 모르겠네요... 손실이 큰 이유는 모든 정답과 오답에 대해서 손실을 더해서 반환하기 때문인 듯 합니다.
Compact CBOW
한편 저번 장에서 입력 원핫벡터를 모두 합쳐서 CBOW를 컴팩트하게 만들어 보았습니다. 방법론이 유효하다는 것을 확인했기 때문에, 이번에도 입력을 합쳐서 모델 효율성을 높여보도록 하겠습니다. 다만 이번에는 입력이 원핫 벡터가 아닌 라벨으로 주어집니다. 따라서 단순히 합치는 것이 아니라 맥락을 모두 엮어주어야(Concatenate) 합니다.
def create_contexts_target(corpus, window_size=1, concat_contexts=False) :
target = corpus[window_size :-window_size]
contexts = []
for idx in range(window_size, len(corpus) - window_size) :
cs = []
for t in range(-window_size, window_size + 1) :
if t == 0 :
continue
if concat_contexts:
cs += [corpus[idx + t]]
else:
cs.append(corpus[idx + t])
contexts.append(cs)
return np.array(contexts), np.array(target)함수에서 concat_contexts 인자를 True로 주면 맥락이 모두 합쳐져 나오도록 구현했습니다. 이에 맞추어 모델도 적절히 구성을 바꾸어주었습니다. 윈도우 개수만큼 레이어가 만들어지는 것이 아니라, 하나의 레이어로 모든 계산을 수행합니다. 이 모델을 Compact CBOW라고 명명했습니다.
class CompactCBOW:
def __init__(self, vocab_size, hidden_size, corpus):
V, H = vocab_size, hidden_size
W_in = 0.01 * np.random.randn(V, H).astype('f')
W_out = 0.01 * np.random.randn(V, H).astype('f')
self.in_layer = Embedding(W_in)
self.ns_loss = NegativeSamplingLoss(W_out, corpus, power=0.75, sample_size=5)
layers = [self.in_layer, self.ns_loss]
self.params, self.grads = [], []
for layer in layers:
self.params += layer.params
self.grads += layer.grads
self.word_vecs = W_in
def forward(self, contexts, target):
h = self.in_layer.forward(contexts).sum(axis=1)
loss = self.ns_loss.forward(h, target)
return loss
def backward(self, dout=1):
dout = self.ns_loss.backward(dout)
self.in_layer.backward(dout)
return NoneCompact CBOW를 이용하여 같은 파라미터로 학습을 진행해 보았습니다.

여전히 불안정한 학습이지만, 그럼에도 불구하고 로스가 하강하는 방향으로 학습을 진행하고 있습니다. 중요한 것은 시간이 절반 정도밖에 소요되지 않는다는 점입니다! (25.69sec → 12.67sec)
아무래도 전체 샘플이 1000개밖에 안되는데 배치사이즈를 너무 크게 잡아서 가중치 업데이트가 덜 되는 것 같습니다. 따라서 배치 사이즈를 절반인 64로 잡아보았습니다.

배치 사이즈가 절반이 된만큼 시간이 2배 더 들지만, 훨씬 더 안정적으로 학습하는 모습입니다. 기존 CBOW도 마찬가지로 배치 사이즈를 줄여 학습시켜 보았습니다.

마찬가지로 조금 더 안정적인 학습이 가능하지만, 시간은 역시 2배 더 소요되었습니다. 어쨌든 CBOW를 컴팩트하게 만드는 것은 성공적인 듯 합니다. 다만 이전 장에서 Skip-gram과 같이 출력이 다수인 경우에는 하나로 통합시키는 것이 불가능하다는 것을 경험적으로 알아냈으므로, 튜닝은 CBOW까지만 해보도록 하겠습니다.
Compact CBOW를 사용하여 TBA 데이터셋 전체를 학습하는 모습입니다.

Encoder vs Decoder representation
이전에 인코더의 분산표현과 디코더의 분산표현을 비교해보기로 했었죠. Compact CBOW로 학습시킨 뒤 디코더의 분산표현을 사용하여 가장 유사한 단어를 구해보았습니다.

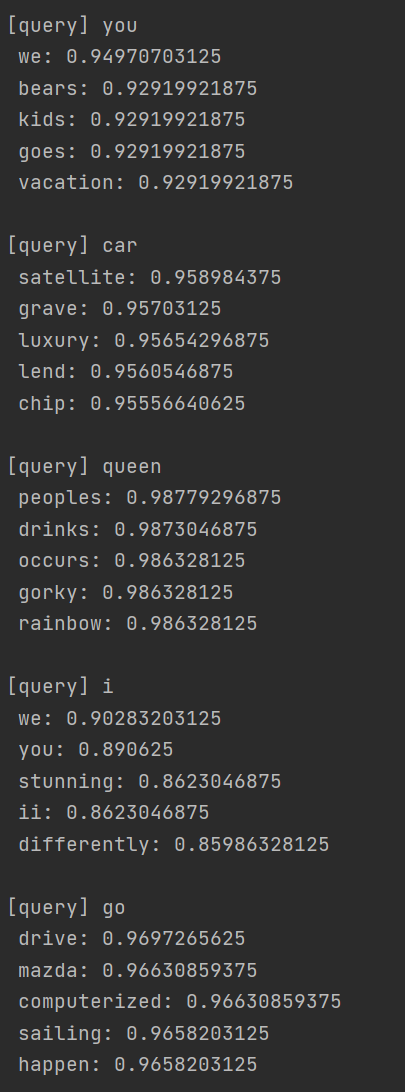
몇몇 단어에 대해 인코더와 유사한 결과가 나오긴 하지만, 대체로 상관성이 더 높고 실제 직관과의 매칭은 떨어지는 느낌입니다. 디코더가 상대적으로 어려운 일을 하는 데 비해서 데이터가 100만 문장밖에 안되서 그런듯 합니다.. 아마 조금 더 대규모 코퍼스에 대해서 학습시키면 디코더의 분산표현이 인코더와 유사해지거나 혹은 능가할 수도 있을거라 생각합니다.
여기까지 Word2Vec을 이용하여 단어를 Distributed representation으로 바꾸어 보았습니다. 이렇게 얻은 분산 표현은 두 가지 측면에서 이점이 있습니다.
1. 전이 학습이 가능합니다.
2. 단어를 고정 길이 벡터로 변환합니다.
따라서 Word2Vec을 이용한 임베딩은 모델 훈련 차원에서 훨씬 더 유용한 형태로 바꾸어 준다고 말할 수 있습니다. 또한 전이학습에 앞서 분산 표현의 품질을 평가하는 경우, 두 가지 측도를 사용할 수 있습니다.
첫 번째는 유사성 평가로, 인간이 직접 단어간 유사도를 정성평가 한 뒤, Word2Vec에 의해 반환된 단어 벡터의 코사인 유사도를 구하여 둘의 상관계수를 구하는 것입니다. 두 번째는 'king:queen = man:?'와 같이 문제를 만들어, 벡터를 실제로 연산하고 정답을 평가하는 방법입니다. Glove의 논문에서는 실제로 이러한 평가를 활용했으며, 결론을 요약하면 다음과 같습니다.
1. 모델(CBOW, Skip-gram)에 따라 정확도가 다르다
(일반적으로 말뭉치 크기가 작으면 Skip-gram이 잘 동작하는 듯)
(대규모 코퍼스에 있어서 의미적으로는 Skip-gram이, 문법적으로는 CBOW가 우세)
2. 코퍼스가 방대할 수록 결과가 좋다.
3. 임베딩 차원 수는 적당한 크기가 좋다.
다음 장에선 드디어 기다리고 기다리던 순환 신경망을 구현합니다.
'독서' 카테고리의 다른 글
| Ch6. 게이트가 추가된 RNN (0) | 2021.07.29 |
|---|---|
| Ch5. 순환 신경망(RNN) (0) | 2021.07.28 |
| Ch3. Word2Vec (0) | 2021.07.26 |
| Ch2. 자연어와 단어의 분산 표현 (0) | 2021.07.25 |
| Ch1. 신경망 복습 (0) | 2021.07.24 |



