
while (1): study();
[논문 리뷰] On Layer Normalization in the Transformer Architecture 본문
출처: https://arxiv.org/abs/2002.04745
On Layer Normalization in the Transformer Architecture
The Transformer is widely used in natural language processing tasks. To train a Transformer however, one usually needs a carefully designed learning rate warm-up stage, which is shown to be crucial to the final performance but will slow down the optimizati
arxiv.org
1. Introduction
Transformer는 현재 자연어처리 외의 각종 영역에서 빛을 발하고 있는 SOTA 아키텍처입니다. 다만 초기에 제시되었던 post-LN 방식의 구조는 훈련시키기가 상당히 까다로웠던 것은 사실입니다. Transformer의 학습 초기 그래디언트가 상당히 불안정했기 때문에, 불가피하게 warm-up stage를 거칠 수 밖에 없었습니다. 이것은 두 가지 측면에서 단점이라고 볼 수 있습니다.
1. 훈련을 느리게 만듭니다.
2. 더 많은 파라미터 튜닝을 요구합니다 - 특히 최대 learning rate와 warm-up iteration에 민감합니다.
이러한 warm-up stage를 배제하기 위해서 저자들은 pre-LN 구조에 집중합니다. 이것은 Layer Normalization을 residual connection의 안쪽으로 이동시킨 구조이며, 마지막 출력 직전에 final-layer normalization을 또한 추가합니다.
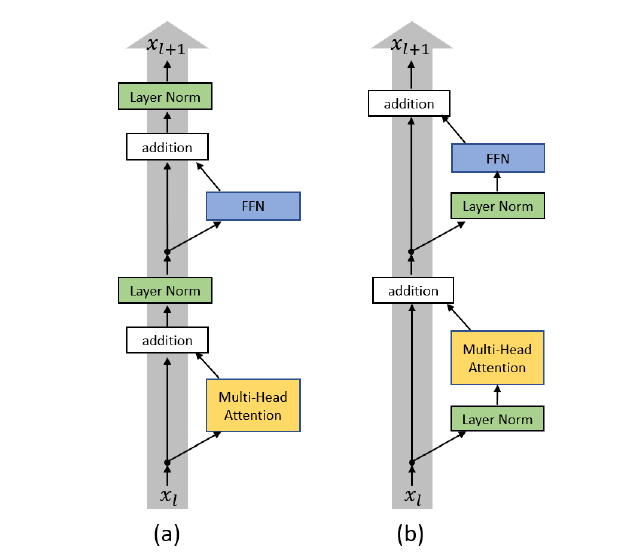
3. Optimization for the Transformer
Transformer의 구조에 대해서는 이전에 다루었기 때문에 자세한 설명을 생략합니다. 필요하신 분들은 아래 링크를 참조해주시기 바랍니다.
링크 ↓
링크: https://jcy1996.tistory.com/8?category=956484
[논문 리뷰] Attention is All You Need
출처 : https://arxiv.org/abs/1706.03762 Attention Is All You Need The dominant sequence transduction models are based on complex recurrent or convolutional neural networks in an encoder-decoder co..
jcy1996.tistory.com
다만 Post-LN에 사용될 warm-up에 관해서는 조금 살펴보도록 하겠습니다. warm-up을 사용할 때 learning rate는 다음과 같이 책정됩니다.

warm-up iteration을 T_warmup으로 표현할 때, 해당 iteration에 이르기까지 균등한 비율로 learning rate를 최대(lr_max)까지 증가시킵니다. 이는 결과적으로 Transformer의 초기 불안정한 그래디언트에 대해 덜 학습하게 하고, 시간이 지날수록 안정된 그래디언트를 학습시킵니다. 일반적으로 lr_max를 달성한 이후에는 선형적으로 learning rate를 감소시켜 최적해를 찾도록 합니다. 이를 linear learning rate decay라고 합니다.
어쨌든 여기서 중점은 이 warm-up stage를 post-LN의 학습과정에서 제거할 수 있는가입니다. Adam과 SGD를 사용하여 실험해 본 결과는 다음과 같습니다.

위의 실험 결과를 보면 두 가지 결론을 낼 수 있습니다.
1. Post-LN 구조에서 learning rate warm-up stage는 불가피합니다.
2. warm-up stage는 T_warmup(warm-up iteration)에 굉장히 민감합니다.
post-LN에서는 답이 없는 듯하니, pre-LN에서 그 답을 찾아보려 합니다. 일찍이 Transformer의 레이어 개수가 증가하면 증가할수록 pre-LN이 post-LN의 성능을 상회한다는 결과가 있었습니다. 그 이유를 이론적으로 찾아보면 핵심은 다음과 같습니다. post-LN의 경우 전체 시퀀스의 손실에 대한 그래디언트는 다음과 같습니다.

전체 시퀀스의 손실을 블록의 마지막 FC 레이어의 가중치로 미분한 것은 즉 그래디언트입니다. 이 그래디언트의 프로베니우스 놈은 빅오 표기법을 따라 O(d log(ln d)) 이하입니다. 따라서 레이어의 개수에 전혀 영향을 받지 않습니다.
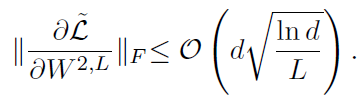
Pre-LN은 그래디언트가 O(d log(ln d / L)) 이하입니다. 그 말은 즉슨 레이어의 개수에 의해 그래디언트가 scaling되는 효과를 누릴 수 있다는 것입니다.
정리하자면 Post-LN 방식은 그래디언트가 레이어의 개수와 독립적 관계이며, Pre-LN은 logL로 스케일링되는 선형적 관계입니다. 시각적으로는 다음 그래프를 통해 확인할 수 있습니다.

Post-LN 방식으로 학습한 경우 warm-up을 거치지 않으면 레이어의 개수가 늘어날수록 그래디언트의 기댓값이 커지는 경향을 보입니다. 그러나 Pre-LN의 경우 레이어가 늘어나더라도 기댓값은 거의 일정한 모습을 보이며 심지어 점차 줄어드는 경향까지 보입니다. (c)와 (d)는 FFN의 마지막 FC layer 그래디언트 기댓값인데, Post-LN은 기댓값이 Pre-LN에 비해 상당히 크다는 것을 알 수 있습니다.
4. Experiments
모종의 실험을 통해서 저자들은 몇가지 유용한 결론들을 도출해낼 수 있었습니다.
1. Pre-LN Transformer는 더 이상 learning rate warm-up stage를 필요로 하지 않습니다.
2. 같은 lr_max를 사용한다고 가정할 때, Pre-LN의 수렴속도가 Post-LN보다 빠릅니다.
3. Layer Normalization을 사용하는 것이 Optimizer를 RAdam으로 바꾸는 것보다 성능 향상에 더 크게 기여합니다.
세 번째 경우는 다음의 실험 결과를 보면 알 수 있습니다.

Post-LN을 사용한다는 가정하에 Adam을 사용했을 때와 RAdam을 사용했을 때의 성능 차이는 크지 않습니다. 그러나 Pre-LN을 사용했을 때는 Optimizer의 종류와는 상관없이 좋은 성능을 보이는 것이 확인됩니다.
정리
결론적으로 초기의 너무 큰 그래디언트가 불안정한 학습을 야기하였고, 이를 방지하기 위해 Pre-LN을 사용할 경우 그래디언트를 레이어의 개수로 스케일링하는 꼴이 되어 안정된 학습이 가능했습니다. Residual Connection으로 identity function을 더해주면서 그래디언트가 커지므로, 더해지기 전에 작게 만들어버리자! 라는 건 누구나 생각할 법한 사실인데, 그 처음이 항상 어려운 듯합니다..
이후에 Layer Normalization을 다른 위치에도 넣어 실험해볼 것이라는데, 또 다른 최적점이 발견될지 이후 실험결과가 궁금해지는 대목이네요.
'논문 리뷰' 카테고리의 다른 글
| [논문 리뷰] Dual Learning for Machine Translation (0) | 2021.07.07 |
|---|---|
| [논문 리뷰] CatBoost: unbiased boosting with categorical features (0) | 2021.07.05 |
| [논문 리뷰] Understanding Back-Translation at Scale (0) | 2021.07.01 |
| [논문 리뷰] Attention is All You Need (0) | 2021.07.01 |
| [논문 리뷰] Train longer, generalize better: closing the generalization gap in large batch training of neural networks (0) | 2021.06.27 |



