
while (1): study();
[논문 리뷰] CatBoost: unbiased boosting with categorical features 본문
출처: https://arxiv.org/abs/1706.09516
CatBoost: unbiased boosting with categorical features
This paper presents the key algorithmic techniques behind CatBoost, a new gradient boosting toolkit. Their combination leads to CatBoost outperforming other publicly available boosting implementations in terms of quality on a variety of datasets. Two criti
arxiv.org
사실 이번에 개인적으로 진행하고 있는 대회에서 CatBoost를 상당히 유용하게 쓰고 있음에도 불구하고, 정작 그 내부에 대해서는 제대로 모르는 것 같아 불편한 마음에 논문을 읽고 리뷰해볼까 합니다... 사실 가장 큰 계기를 얻게 된 건 CatBoost 내부에서 Categorical feature를 다루는 방식이 일반적인 방식과는 다르게 성능을 향상시켰다고 해서, 그것을 중점적으로 한번 살펴보려고 합니다.
1. Introduction
그래디언트 부스팅이란 Decision Tree기반 predictor를 중첩시켜 '못 푸는 문제'에 대해 학습시키는 것입니다. 점차 최적해를 찾아간다는 점에서 딥러닝의 Gradient Descent를 수행하는 것과 유사하다고 볼 수 있습니다. 다만 여기선 기존 그래디언트 부스팅 방식의 단점에 집중하고 있습니다. 이는 Prediction shift라고 하는 현상입니다.
Gradient Descent와 유사한 방식으로 수행되기 때문에, 손실을 계산하려면 정답이 필요하고, 따라서 여러번 학습을 하면 할 수록 모델은 훈련데이터의 정답에 의존하게 됩니다. 논문에서는 '이러한 연유로 테스트 샘플의 분호가 훈련 샘플의 분포로 이동하는 과정이 prediction shift다!' 라고 거창하게 써놨습니다만, 사실 그냥 정답 유출(target leakage), 그리고 어떻게 보면 과적합(overfitting) 현상이라고도 할 수 있겠죠.
어쨌든 CatBoost는 Ordered Boosting이라는 방법을 통해 이런 단점을 잡았다고 합니다.
2. Background
그래디언트 부스팅은 기본적으로 다음과 같은 수식을 따라 계산됩니다.
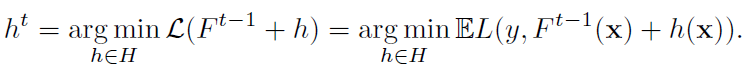
h는 Predicator를 의미하며, 즉 이전 결과에 대해서 Predicator를 추가하며 재귀적으로 손실을 최소화시킵니다. 최소화는 뉴턴 방식을 이용합니다. 즉, 테일러 정리를 이용하여 일차함수를 가정하고, 최적해의 근사치를 구합니다.
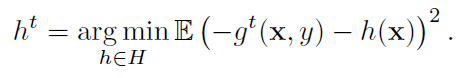
Predicator는 negative gradient를 근사하는 방향으로 생성된다는 것을 알 수 있습니다.
3. Categorical features
핵심이 되는 부분입니다. 기존의 one-hot encoding 방식은 high-cardinality feature(범주의 수가 매우 많은 경우)에 대해서 너무 많은 새로운 features를 생성합니다. LightGBM은 gradient statistics를 사용하여 인코딩하지만, 이 경우 1) 연산 시간이 너무 많이 소요되고 2) 메모리를 너무 많이 사용한다는 단점이 있습니다. 그렇기 때문에 카테고리를 하나의 클러스터로 뭉쳐서 계산하지만, 결과적으로 정보의 손실이 발생하게 됩니다.
따라서 CatBoost는 TS(Target Statistics)를 사용합니다. 일반적인 Greedy TS는 다음과 같이 계산합니다.

즉 범주에 대해서 타겟의 기댓값을 구하되, 이러한 방법은 빈도가 낮은 범주에 대해서 noisy한 단점이 있기 때문에, p를 더하여 스무딩해줍니다. (일반적으로 p는 타겟값의 평균입니다.)
문제는 이 경우 target leakage가 발생한다는 것입니다. 따라서 이를 해결하기 위한 다른 방법론이 필요합니다. 따라서 Holdout TS를 고려해볼 수 있습니다. 이는 TS를 계산하는 데이터와 실제 트레이닝 데이터를 나누는 것인데, 이 경우엔 실제 데이터를 다 사용할 수 없다는 것이 문제가 됩니다. 따라서 우리가 고려해야 할 사항은 두 가지입니다.
1. Target leakage가 발생하는가?
2. 주어진 데이터를 모두 사용할 수 있는가?
그리하여 대두한 것이 Ordered TS입니다. 훈련 데이터를 random permutation한 뒤, 바로 직전까지 TS만 사용하여 TS를 계산합니다. 결과적으로 해당 샘플의 타겟을 사용하지 않는다는 점에서 target leakage를 방지할 수 있으며, 주어진 데이터도 모두 사용할 수 있습니다.
4. Prediction shift
Introduction에서 거론했듯이, negative gradient에 Predicator를 근사시키는 과정에서 정답 정보가 유출되고, F의 분포가 훈련 데이터의 분포로 이전되는 현상입니다. 일종의 target leakage라고 볼 수 있습니다.
5. Practical implementation of ordered boosting
이를 해결하기 위해 Ordered boosting을 사용합니다. 위에서 살펴본 Ordered TS와 방법론적으로 상당히 유사합니다. 부스팅 모델을 random permutation한 뒤 이전까지의 모델만 사용하는 것입니다. 단, 이때 random permutation은 Ordered TS를 수행할 때의 random permutation과 같아야 합니다. 둘이 다를 경우 target leakage가 다시 발생할 수 있기 때문입니다. 의사코드는 다음과 같습니다.

모델에 관련해서 흥미롭게 본 점은 categorical features를 combination할 수 있다는 점입니다. 실제로 사용해본 적은 없는 기능인데, 시도해볼 필요성은 충분하다고 생각합니다.
정리
결국 관건이 되는 것은 target leakage였고, 이를 해결하기 위해서 이전 시점까지의 요소만 사용하는 방법론을 인코딩과 부스팅에 적용한 것이 바로 CatBoost였습니다. 사실 CatBoost의 파라미터가 워낙 많아서 하나하나에 대한 이해를 좀 더 깊게 하고자 하는 목적도 있었습니다만, 생각보다 내용이 구체적이진 않은 것 같아서 아쉬웠습니다.
'논문 리뷰' 카테고리의 다른 글
| [논문 리뷰] Dual Transfer Learning for Neural Machine Translation with Marginal Distribution Regularization (0) | 2021.07.08 |
|---|---|
| [논문 리뷰] Dual Learning for Machine Translation (0) | 2021.07.07 |
| [논문 리뷰] On Layer Normalization in the Transformer Architecture (0) | 2021.07.02 |
| [논문 리뷰] Understanding Back-Translation at Scale (0) | 2021.07.01 |
| [논문 리뷰] Attention is All You Need (0) | 2021.07.01 |



