while (1): study();
[논문 리뷰] Dual Transfer Learning for Neural Machine Translation with Marginal Distribution Regularization 본문
[논문 리뷰] Dual Transfer Learning for Neural Machine Translation with Marginal Distribution Regularization
전국민실업화 2021. 7. 8. 15:45출처: https://dblp.org/rec/conf/aaai/WangXZBQLL18.html
dblp: Dual Transfer Learning for Neural Machine Translation with Marginal Distribution Regularization.
For web page which are no longer available, try to retrieve content from the of the Internet Archive (if available). load content from web.archive.org Privacy notice: By enabling the option above, your browser will contact the API of web.archive.org to che
dblp.org
마이크로소프트 사에서 Dual Learning에 대해 연구 및 발표한 자료입니다.
Introduction
Dual Learning(이하 DL)의 목표가 Monolingual Corpus를 효율적으로 사용하는 것이니만큼, 다시 한번 LM Ensemble, BT, 그리고 이전까지의 DL 등을 거론하고 있습니다. 이들은 이전까지의 DL이 MRT를 사용했기 때문에 매우 비효율적이라는 것을 인지하고 있었습니다. 그렇기 때문에 이 문제를 해결하고자 Dual Transfer Learning을 제안합니다. 쉽게 말하자면 "Dual model이 학습한 내용을 실제 번역 모델에 전이시키자!"는 것입니다.
이때 사용될 DL model의 Regularization term을 도출해야 합니다. 우선 P(y)는 전체 확률의 법칙(The law of total probability)에 의해 다음과 같습니다.

단, 문제가 있습니다. X의 search space가 너무나도 크기 때문에, P(x)는 물론 거의 0에 가까운 값일 것입니다. 또한 모든 x에 대해서 조건부 확률을 구하는 것도 불가능한 일이기 때문에 우리는 몬테 카를로 방법을 이용하여 근사한 식을 사용할 것입니다.

이렇게 하면 큰 Search Space의 문제는 해결되지만, sampling이기 때문에 발생하는 고질적인 문제가 있습니다. x를 K개 sampling한다고 하더라도 대부분의 x는 y과 관련이 없을 것이기 때문에 조건부 확률은 대부분의 경우 0에 가까운 값일 것입니다. 따라서 해당 논문에서는 importance sampling이라는 방법을 사용합니다. 이것에 관해서는 이후 챕터에서 다루겠습니다.
Framework
일반적인 MLE기반 기계번역기의 Log-likelihood 다음과 같이 정의됩니다.
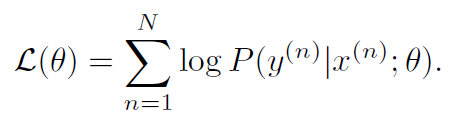
또한 우리는 앞서 Introduction에서 전체 확률의 법칙에 의해 P(y)가 다음과 같이 정의될 수 있음을 확인했습니다.

따라서 가능도를 최대화(Maximum likelihood)한다는 말은 다음과 같이 다시 정의될 수 있습니다.

위 식에서 조건이 되는 term을 정리하여 새로운 regularization term으로 만들면 다음과 같습니다. 단, 우리는 P(y)에 대해서 일반적으로 접근할 수 없기 때문에, Language Model을 따로 학습하여 P_hat(y)를 구한 것입니다.

그렇다면 새로운 term을 적용하여 새로운 Training Objective를 써볼 수도 있을 것입니다. 우변의 좌항은 Bilingual Corpus로 학습한 모델에 대한 손실이며, 우항은 Monolingual Corpus로 학습한 모델에 대한 손실이 될 것입니다.

단 앞서 말한 문제는 여전히 남아 있습니다. sampling을 사용하여 조건부 확률을 계산할 경우 대부분은 x와 y가 관계가 없을 것(irrelevant)이기 때문에, 우항의 regularization이 부적절해질 가능성이 높습니다. 따라서 더 효율적으로 sampling하기 위해서 importance sampling이라는 기법을 도입합니다.
importance sampling이란 '조금 더 그럴듯한 분포에서 sampling할 수 있도록 분포를 다시 정의하는 작업'을 동반합니다. 다음 식을 봅시다.
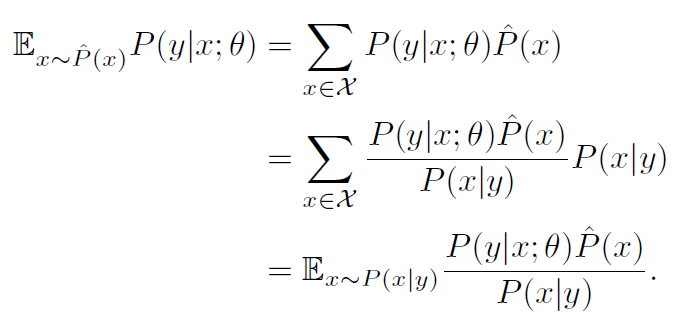
분자와 분포에 각 P(x|y)를 곱해준다면 양변은 여전히 등호가 성립함이 분명합니다. 따라서 우리는 P_hat(x)로부터 sampling을 하는 결과와 P(x|y)에서 sampling을 하는 결과가 같다는 것을 확인할 수 있습니다. 다만 P(x|y)에서 sampling할 경우 x와 y가 더욱 관계가 있다(relevant)는 사실을 직관적으로 알 수 있을 것입니다.
Importance sampling이 적용된 식을 다시 몬테 카를로를 이용하여 근사합니다.

이를 바탕으로 새롭게 정의된 Regularization term은 다음과 같습니다.

결국 손실은 다음과 같이 정의됩니다.

Experiments
Marginal Distribution을 이용하여 정의된 새로운 Regularization term이 추가되었을 때, 얼마나 성능이 향상되는지 확인해보도록 하겠습니다. 아래 그림은 unlabeled data, 그러니까 Monolingual corpus의 Bitext대비 비율입니다.

약 0.8 정도까지 꾸준히 증가하다가 비율이 1:1이 되는 순간 증가 추세가 더뎌지는 듯 합니다. 데이터를 너무 많이 추가하면 시간만 많이 먹고 성능 향상에는 큰 의미가 없을지도 모르겠네요. 논문에서는 1의 비율을 사용했다고 합니다. 또한 Bilingual 모델과 Monolingual 모델의 비율을 조정하는 파라미터인 람다에 대해서도 실험 결과가 있습니다.

최적의 파라미터는 0.05였고 여기서 조금만 올라가거나 내려가도 성능이 꽤 달라지는 것이 보입니다. 이 구조는 람다에 상당히 민감한 아키텍처네요. 어쨌든 최종 결과는 다음과 같습니다.
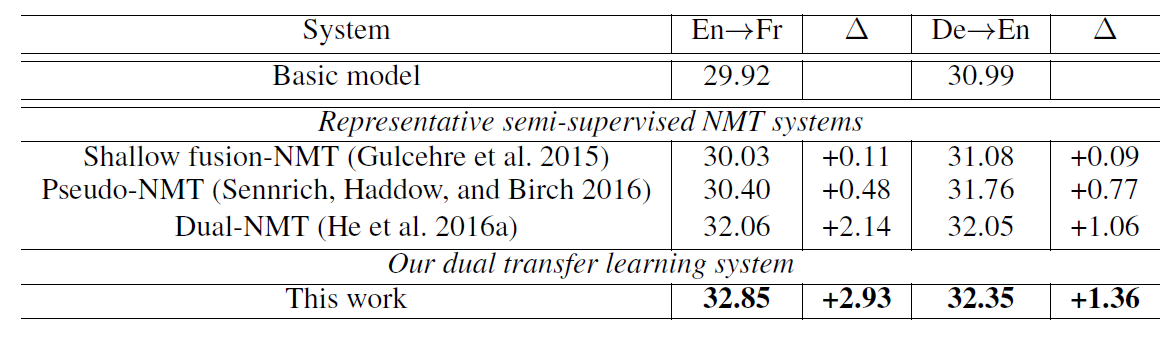
LM ensemble, BT, 그리고 MRT기반 DL에 비해서 월등히 높은 BLEU score를 보이고 있음을 알 수 있습니다. 사실 이전의 Dual-NMT가 워낙 비효율적이기 때문에 비슷한 정도의 성능만 보여줘도 MLE 위에서 돌아가는 알고리즘이기 때문에 충분히 경쟁력있을 거라고 봅니다만, 사실상 MRT 기반 DL은 사용할 이유가 없다고 보이는 결과네요.
정리
일전의 Dual Learning for Machine Translation은 MRT 기반이었고, 따라서 속도가 매우 느릴 뿐 아니라 미분 시 방향도 알 수가 없었습니다. 그 단점을 해결한 것이 바로 이 논문인 듯합니다. 뿐만 아니라 수학적으로 전개가 아주 깔끔한 것 같아서 좋네요.
머신러닝에 있어서 수학은 중요하다! 중요하지 않다! 여러 사람의 얘기를 들어본 것 같지만, 저는 역시 수학은 중요하다고 생각합니다. 이런 멋진 방법론을 생각할 수 있게 하는 것 뿐만 아니라, 멋진 얘기를 들을 수 있게 해주기 때문입니다.
'논문 리뷰' 카테고리의 다른 글
| [논문 리뷰] Using the Output Embedding to Improve Language Models (0) | 2021.07.13 |
|---|---|
| [논문 리뷰] The University of Edinburgh's Neural MT Systems for WMT17 (0) | 2021.07.09 |
| [논문 리뷰] Dual Learning for Machine Translation (0) | 2021.07.07 |
| [논문 리뷰] CatBoost: unbiased boosting with categorical features (0) | 2021.07.05 |
| [논문 리뷰] On Layer Normalization in the Transformer Architecture (0) | 2021.07.02 |