while (1): study();
[논문 리뷰] The University of Edinburgh's Neural MT Systems for WMT17 본문
출처: https://aclanthology.org/W17-4739/
The University of Edinburgh’s Neural MT Systems for WMT17
Rico Sennrich, Alexandra Birch, Anna Currey, Ulrich Germann, Barry Haddow, Kenneth Heafield, Antonio Valerio Miceli Barone, Philip Williams. Proceedings of the Second Conference on Machine Translation. 2017.
aclanthology.org
BT(Back Translation)과 BPE(Byte Pair Encoding)로 유명한 Rico Sennrich 교수팀이 WMT17에 제출한 기계번역기에 관련한 내용입니다. 정말 직관이 대단하다고 생각하는 사람 중 한명인데다가, 단일 GPU를 사용하여 작년 모델 대비 BLEU를 2.2에서 5 정도 끌어올렸다고 하니 안 읽어볼 수가 없었습니다. 어떻게 해서 효율적으로 성능을 향상시켰는지 확인해보도록 하겠습니다.
1. Introduction
작년의 WMT16에 제출한 모델에 비해 WMT17의 모델은 다음과 같은 점이 바뀌었다고 합니다.
1. 더 깊은 모델
2. Monolingual data를 활용할 새로운 방법
3. 색다른 앙상블 기법
4. 개선된 BPE 알고리즘
5. Weight tying
6. Layer Normalization & Adam optimizer
2. Novelties
위에서 거론한 새로운 변화들을 이 챕터에서 하나하나 짚어보려고 합니다.
2.1. 더 깊은 모델
모델 아키텍처는 Deep Transition Architecture와 Stacked Architecture를 나누어 실험해본 것 같습니다만, 주로 전자를 사용했다고 합니다.
2.1.1. Deep Transition Architecture
우선 Deep Transition Architecture는 일반적인 RNN 기반 인코더와는 다릅니다. 심플한 RNN 인코더가 모든 타입스탭에 대해서 한방에 계산을 하는데 비해서 Deep Transition Architecture에서는 순차적으로 계산합니다. 이를 multiple GRU Transition이라고 표현하였습니다. GRU(Gated Recurrent Unit)를 사용했다는 것도 알 수 있네요.
여기서 Transition이라는 단어가 많이 나오는데, Transition function은 현재 상태와 입력을 받아서 다음 상태를 반환하는 함수를 말합니다. 즉, RNN계열 레이어가 통상적으로 하는 일이 Transition이라고 보면 될 것 같습니다.
어쨌든 인코더는 다음과 같이 수식으로 표현할 수 있습니다.

이전 타임스탭의 마지막 출력과 해당 타입스탭의 단어를 입력으로 받아서 해당 타임스탭의 hidden state를 출력합니다. 이후에는 깊이축을 따라서 연산을 진행하네요. 양방향 연산같은 경우 마지막 깊이에서 출력할 때 순방향 출력과 역방향 출력을 concatenation해주었다고 합니다.
디코더는 인코더와 비슷한 아키텍처입니다만 Attention이 추가된 것 뿐입니다. 수식을 살펴보겠습니다.
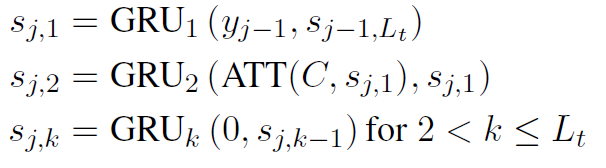
인코더와 유사하게 첫번째 레이어에서는 이전 타임스탭의 마지막 레이어의 출력과, 해당 타임스탭의 단어를 입력으로 받습니다. 다만, 두 번째 레이어에서는 첫 번째 레이어로부터 Attention 연산된 Context vector가 필요하게 됩니다. 다음 타임스탭부터는 인코더와 마찬가지로 깊이축을 따라 연산해줍니다. GNMT 논문에서 효율적인 병렬처리를 위해서 인코더의 마지막 레이어와 디코더의 첫 레이어에만 Attention을 걸었었는데 그것와 마찬가지인 듯 합니다. GNMT 포스팅은 아래에 링크를 달아놓겠습니다.
↓ 링크
GNMT: https://jcy1996.tistory.com/3?category=956484
[논문 리뷰] Google's Neural Machine Translation System: Bridging the Gap between Human and Machine Translation
ArXiv 링크: https://arxiv.org/abs/1609.08144 Google's Neural Machine Translation System: Bridging the Gap between Human and Machine Translation Neural Machine Translation (NMT) is an end-to-end lear..
jcy1996.tistory.com
Deep Transition Architecture 같은 경우 인코더의 깊이는 4, 디코더의 깊이는 8로 잡았다고 합니다.
2.2.2. Stacked Architecture
이는 일반적인 RNN 인코더 디코더 구조와 유사합니다. 단, Residual Connection이 추가되어 더 깊은 층을 쌓을 수 있습니다. 또한 첫번째 레이어에서 순방향 연산을 시킨 뒤, 짝수 번째 레이어에 대해서는 역방향, 홀수 번째 레이어에 대해서는 다시 정방향으로 번갈아가며(Alternating direction) 양쪽 방향에 대한 의존관계를 학습시킵니다. 수식은 다음과 같습니다.
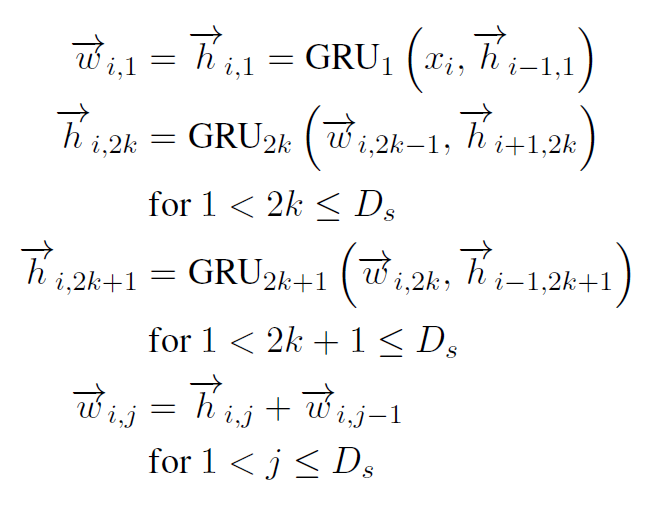
i번째 타임스탭의 첫 번째 레이어는 이전 타임스탭의 첫 번째 레이어와 단어를 입력으로 받습니다. 이후 2k 번째 레이어는 역방향 연산을, 2k + 1 번째 레이어는 순방향 연산을 번갈아 진행하는 것을 알 수 있습니다. 마지막에는 Gradient Vanishing을 방지하기 위해 Residual Connection까지 진행해줍니다.
디코더는 이와 같은 구조이지만 방향을 번갈아 연산하는 것만 없을 뿐입니다. 디코더의 경우 역방향 연산을 취하면 illegal connection이 됩니다. Stacked Architecture의 인코더와 디코더는 모두 깊이 4를 줬다고 합니다.
2.2. Monolingual data를 활용할 새로운 방법
WMT16에 제출할 때는 단순히 BT만 사용했다고 합니다. 그러나 WMT17에서는 두 가지 방법론을 제안했습니다.
첫 번째 mixed approach는 훈련 초기부터 병렬 코퍼스와 합성 코퍼스(Synthetic data; BT로 생성된 병렬 코퍼스)를 섞어서 사용합니다. 반면 fine-tuned approach는 훈련 시 오직 병렬 코퍼스만 사용하며, 어느정도 수렴하고 난 뒤 mixed approach와 같이 혼합된 코퍼스를 사용하여 fine-tuning합니다.
두 경우 모두 혼합 비율은 1:1이었으며, mix approach는 빠르게 동작하는 반면, fine-tuned approach는 특정 도메인에 더 잘 적합된다고 합니다.
한편, 영어 ↔ 터키어 번역 task의 경우 Copied Translation이 잘 먹혔다고 합니다. 여기서 Copied Translation이란 코퍼스가 부족한 언어에 대해서 디코더의 언어모델을 더 풍부하게 학습시키기 위해 입력과 출력을 동일하게 주어 학습시키는 것을 말합니다. 이 경우 병렬 코퍼스와, Copied 코퍼스, BT 코퍼스를 1:2:2 비율로 섞어서 사용했다고 합니다.
2.3. 색다른 앙상블 기법
앙상블은 두 가지 기법을 사용하였습니다. 첫 번째는 Checkpoint Ensemble입니다. 이는 마지막 N개의 체크포인트 모델에 대해서 앙상블하는 방법입니다. 상대적으로 자원이 덜 소모되는 방법이며 WMT16의 제출에 이 방법을 썼다고 합니다. 참고로 모델은 조기종료 에포크를 10으로 주고 학습했습니다.
두 번째는 Independent Ensemble입니다. 익히 잘 알고 있는 앙상블 기법으로, 서로 다르게 학습시킨 독립적인 모델 N개를 앙상블하는 방법입니다. 자원이 많이 소모되지만, 더 많은 다양성을 산출할 수 있다는 장점이 있습니다.
2.4. 개선된 BPE 알고리즘
서브워드를 이용하면 일반적인 단어 토크나이징보다는 훨씬 희소성을 줄일 수 있겠습니다만, Training data에 대해서 통계적으로 단어를 분리시킬 경우 test data에 대해서 여전히 OOV가 발생할 수 있습니다. 이 가능성을 해소하기 위해서 여기서는 훈련 데이터의 소스 언어에서 본 서브워드 단위를 test시에 생성합니다.
또한 너무 희소한 서브워드 단위에 대해서 배제하기 위해서 50번 미만으로 출현한 단어를 고려하지 않았습니다. 결과적으로 단어장의 크기를 줄이고 더욱 compact한 모델을 만들 수 있게 된 것입니다. 참고로 영어를 기준으로 단어장의 크기가 80581에서 51092로 줄었다고 하니 거의 40% 가까이(약 37.5%) 줄였다고 볼 수 있겠네요.
2.5. Weight tying
서브워드를 사용함으로써 단어장의 크기를 획기적으로 줄였고, 결과적으로 메모리 사용량을 줄일 수 있었습니다. 거기에 더해서 Weight Tying이라는 기법을 사용하여 메모리 사용량을 더욱 줄였다고 합니다. 이는 간단하게 말하면 Input-to-Embedding의 가중치와 Output-to-Softmax의 가중치를 동일하게 가져가는 것입니다.
예를 들어 Input의 사이즈가 (batch size, length)일 때, Input-to-Embedding은 (batch size, length, hidden size)의 형태로 입력을 바꾸어주는 Matmul 연산을 지원합니다. 한편, Output은 (batch size, length, vocabulary size)와 같은 형태로 나올 것이고, Output-to-Softmax는 (batch size, vocabulary size)의 형태로 변환시키는 작업을 할 것입니다. 이 때 hidden size를 확장하는 작업과 length를 축소시키는 작업을 하나의 가중치로 처리할 수 있다는 것입니다. 단 형태상 같은 가중치를 사용하려면 Output layer의 형태를 (batch size, length, vocabulary size)와 같이 Transpose시켜주어야 합니다.
관련 논문은 저도 아직 읽어보지 않아서, 궁금하신 분들은 아래 링크를 참고하시길 바라겠습니다.
↓ 링크
링크: https://arxiv.org/abs/1608.05859
Using the Output Embedding to Improve Language Models
We study the topmost weight matrix of neural network language models. We show that this matrix constitutes a valid word embedding. When training language models, we recommend tying the input embedding and this output embedding. We analyze the resulting upd
arxiv.org
결과적으로 두 층의 가중치를 하나로 가져갈 수 있어서 연산량과 메모리 사용량을 줄일 수 있게 됩니다.
2.6. Layer Normalization & Adam optimizer
Softmax 층 다음을 제외한 모든 Layer에 Layer Normalization을 적용했다고 합니다. 또한 WMT16에서는 adaldelta를 사용했었는데, 이번에는 Adam을 사용했다고 합니다.
추가적으로 임베딩 차원은 500 또는 512, hidden size는 1024, Adam의 learning rate는 0.0001, 배치사이즈는 60 또는 80(8 - 12GB GPU를 사용했다고 합니다), 문장 최대 길이를 50으로 주고 학습했다고 합니다.
5. Results
총 6개의 언어쌍에 대해서 학습을 진행했으며, 각각 training regime을 달리 하여 최적의 validation BLEU를 보이는 model을 보이도록 앙상블한 듯 합니다. training regime은 너무 국지적인 내용인 것 같아서 생략하고 최종 결과만 보도록 하겠습니다.
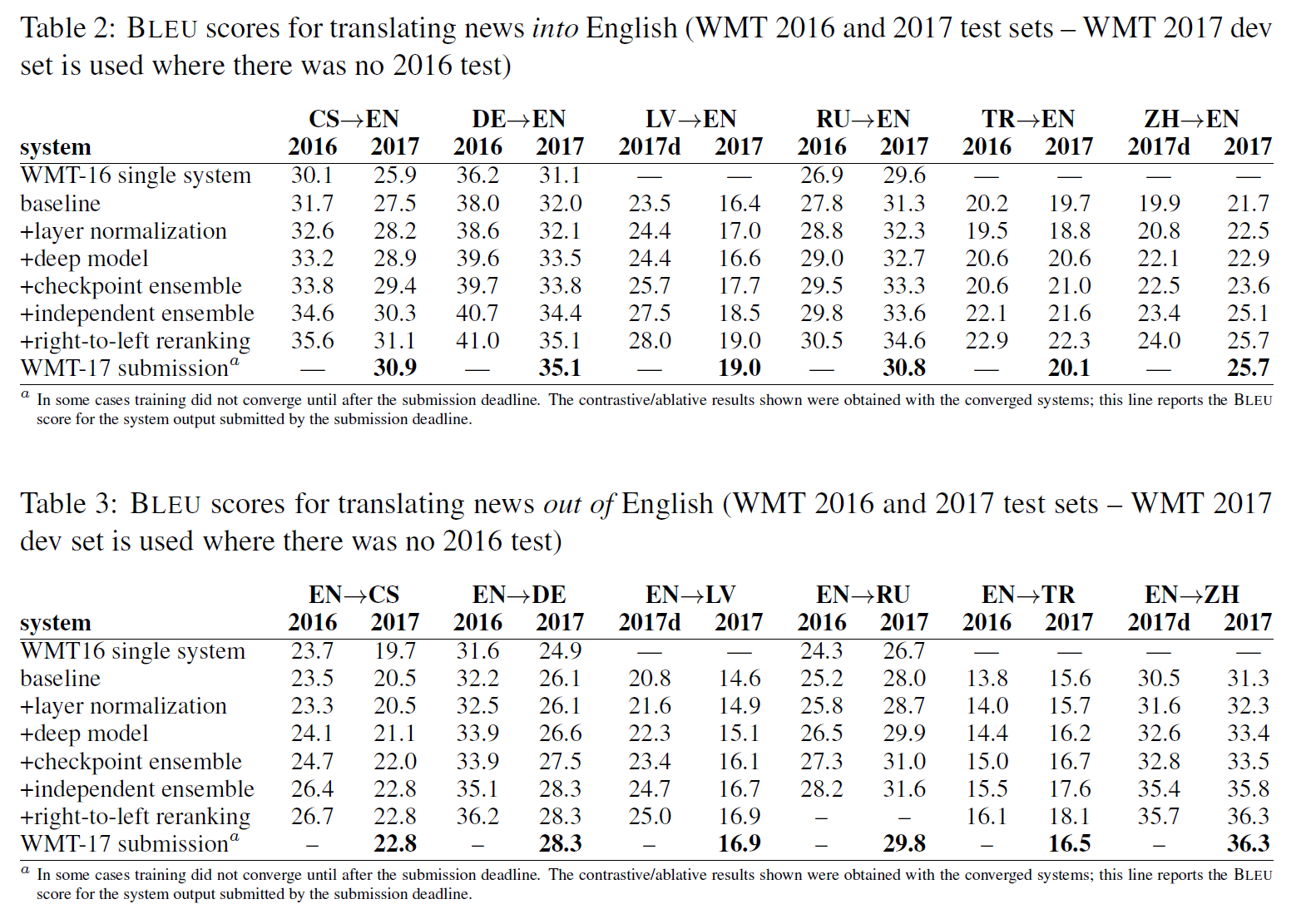
위의 차트는 각 언어의 news 도메인 문장을 영어로 번역해내는 task의 BLEU score이며, 아래 차트는 그 역방향의 task입니다. 베이스라인만 확인해보아도 대부분의 경우 WMT16에 비해 높은 성능을 보이는 것을 알 수 있습니다. 그리고 앞서 확인한 각각의 새로운 요소들을 추가했을 때 점점 더 성능이 높아져, 최종적으로는 WMT16의 성능을 그야말로 압도한 것을 볼 수 있습니다.
여기서 가장 괄목할만한 변화를 보인 요소는 Layer Normalization과 deep model입니다. 두 요소는 모든 task에 대해서 성능이 향상되는 것을 보여 어떤 언어의 번역 task에 있어서도 일반적으로 적용될 수 있는 기법인 듯 보입니다.
정리
단일 GPU로 학습시킬 정도의 부족한 하드웨어 환경에서 어떻게 하면 번역기의 성능을 최대한 끌어올릴 수 있는지 확인해보고자 읽어 보았습니다. 2017년의 모델을 기반으로 쓰인지라 엄청 새로운 내용이 있는 것은 아니지만, Weight Tying이라는 방법론은 상당히 흥미로워서 조만간 알아볼 예정입니다.
또 checkpoint ensemble이나 right-to-left reranking같은 경우 적은 자원으로도 BLEU 향상을 이끌어낼 수 있는듯하여 적극적으로 실험해볼만한 가치가 있다고 생각합니다. 다만 Deep Transition Architecture의 인코더 같은 경우는 Transformer라는 좋은 대체제가 있는 와중에 굳이 사용해야 할 것 같지는 않습니다.
어쨌든 Transformer가 memory issue로 인해 저자원 환경에서 엄청난 훈련시간을 먹는지라, 혹~시 Seq2Seq 기반 번역기를 만들때 참고해볼만한 정도는 될 것 같습니다.