
while (1): study();
[논문 리뷰] Dual Learning for Machine Translation 본문
출처: https://arxiv.org/abs/1611.00179
Dual Learning for Machine Translation
While neural machine translation (NMT) is making good progress in the past two years, tens of millions of bilingual sentence pairs are needed for its training. However, human labeling is very costly. To tackle this training data bottleneck, we develop a du
arxiv.org
이번에 기계 번역기 구현 다 마치고, colab 환경에서 dual learning을 이용한 fine-tuning을 실험해보려고 하는데 시간이 너무 오래 걸려서.. 심심해서 dual learning 관련 논문을 몇 편 읽어보기로 했습니다. 이 논문이 NLP에 적용된 Dual Learning을 최초로 제시한 것으로 알고 있습니다.
1. Introduction
기계번역 모델을 학습시키는데는 양방향 코퍼스(혹은 병렬 코퍼스)가 필요합니다. 즉 A언어에서 B언어로 번역하는 시스템을 만들기 위해서는 방대한 양의 A언어와 B언어 자료가 있어야하며, 이 때 각 언어자료 내의 문장은 의미가 같은 애들끼리 매칭이 되어야 합니다.
하지만 병렬 코퍼스는 비쌉니다. 몇 백만, 몇 천만 개의 문장에 대해서 의미가 같은 문장쌍을 만들어주는 작업을 해주어야 하는데, 인건비가 엄청 많이 들 것입니다. 반면에 단방향 코퍼스는 지천에 널려 있습니다. 구글에 조금만 검색해 보아도 영어부터 필리핀어까지 다양한 언어로부터 많은 양의 문장을 크롤링할 수 있습니다. 그렇기 때문에 이렇게 풍부한 단방향 코퍼스 자원을 싸게 사용하고자 다양한 방법론들이 제시되어 왔습니다.
해당 논문에서는 두 가지 방법론을 거론하고 있네요. 하나는 Language Model(이하 LM) ensemble입니다. 번역 타겟 언어의 단방향 코퍼스를 학습한 LM을 번역기와 결합시켜 결과의 질을 향상 시키는 방식입니다. LM의 학습에는 단방향 코퍼스만 쓰이므로 가능한 방안입니다.
두 번째는 그 유명한 Back Translation(이하 BT)입니다. A에서 B로 가는 번역을 하고 싶을때 우선 B에서 A로 가는 역방향 시스템을 만들고, 역방향 시스템에 실제 B문장을 넣어 가짜 A 문장(Psuedo sentence)를 만듭니다. 물론 가짜 문장은 noisy하겠지만(정확히는 편향되었겠지만), 디코더는 더 풍부한 언어모델을 가질 수 있습니다.
그러나 LM Ensemble의 경우 본질적으로 병렬 코퍼스의 부족을 처리하지는 못하고, BT의 경우엔 합성된 문장의 질을 보장할 수 없다고 합니다. 그리하여 본격적으로 Dual Learning을 제안하게 됩니다. Dual Learning은 다음과 같이 진행됩니다.
1. 첫 번째 agent가 A언어의 문장(a)를 noisy한 B언어의 문장(b)로 번역하여 두 번째 agent로 보냅니다.
2. 두 번째 agent는 b를 받아, 이것이 실제 B의 문장인지 확인합니다.
3. 다시 두 번째 agent는 b를 noisy한 a로 번역하여 첫 번째 agent로 보냅니다.
4. 첫 번째 agent는 원래 자신이 보냈던 메시지와, 두 번째 agent가 보낸 b가 얼마나 비슷한지 확인합니다.
이러한 과정을 논문에서는 일종의 game이라고 합니다. 실제로 마치 핑퐁 게임을 하듯이 문장을 주고받으며, 서로 점수를 매겨주며 학습하는 것이 Dual Learning의 핵심입니다.
3. Dual Learning for Neural Machine Translation
앞서 살펴본 Dual Learning의 진행 과정을 수식으로 좀 더 자세히 살펴보려 합니다. 우리는 지금까지 양방향 코퍼스를 이용하여 A언어에서 B언어로 가는 시스템과, B언어에서 A언어로 가는 시스템을 만들었다고 가정해봅시다. 또한 A언어와 B언어의 단방향 코퍼스도 가지고 있습니다. 여기서 두 단방향 코퍼스는 서로 전혀 관계없는 문장셋이라고 해도 상관없습니다. 우리는 이 단방향 코퍼스를 가지고 번역기의 성능을 끌어올리는 것이 목적입니다.
전체적인 알고리즘은 다음과 같습니다.

천천히 살펴보도록 하겠습니다. 우선 Beam Search를 사용하여 첫 번째 agent(A언어에서 B언어로 가는 시스템)로부터 K개의 문장을 생성합니다. 이 K개의 문장에 대해서 미리 학습한 LM으로 확률을 산출한 것이 바로 첫 번째 agent에 대한 reward가 됩니다. 두 번째 agent에 대한 reward는 communication reward, 혹은 reconstruction reward라고 하는데 생성된 문장과 원래 문장의 로그 가능도를 계산합니다.

따라서 두 시스템의 gradient는 다음과 같이 정의할 수 있습니다. 첫 번째 agent의 loss는 전형적인 Policy gradient method로 계산됩니다. 반면 두 번째 agent의 loss는 단순한 로그가능도로 계산됩니다.

두 모델의 파라미터는 다음과 같이 업데이트됩니다.

이러한 일련의 과정을 두 모델이 최적해에 수렴할 때까지 반복합니다.
4. Experiments
그럼 과연 얼마나 성능이 좋아졌는지 확인해보겠습니다. 영어와 프랑스어, 두 언어 간 Dual Learning을 진행했고 결과는 다음과 같았습니다. (Large는 모든 양방향 코퍼스를 사용한 것, Small은 10%만을 사용한 것입니다.)
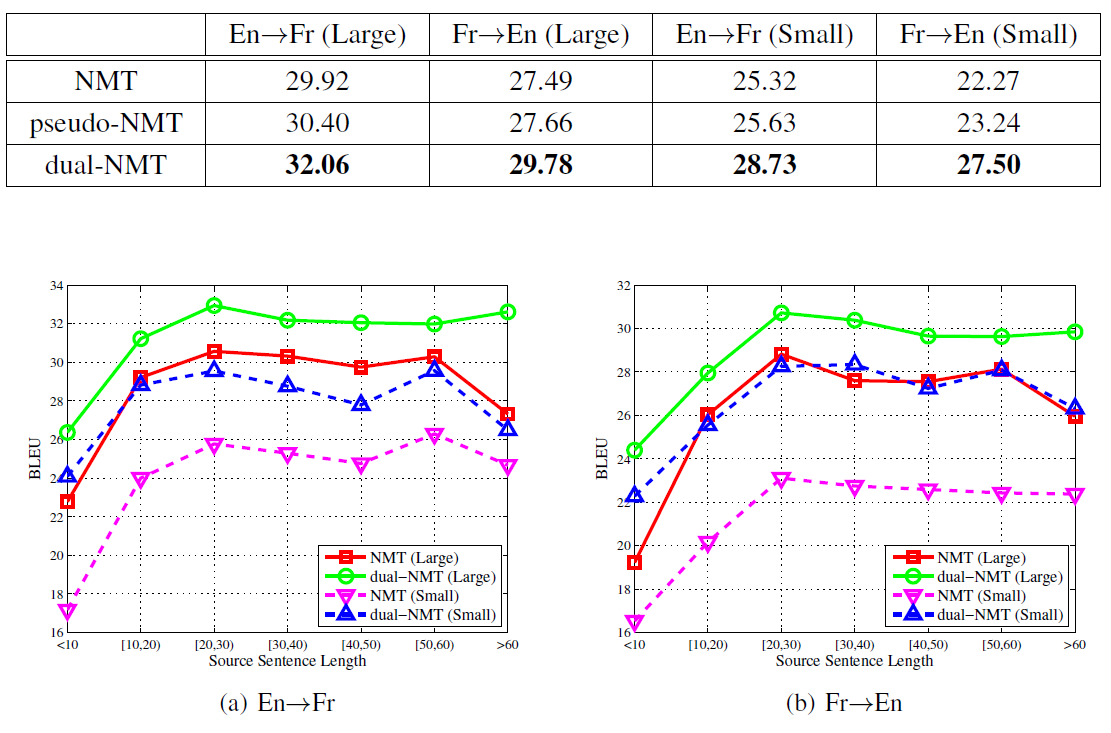
영어에서 프랑스어로 번역하는 경우, low resource인 경우와 high resource인 경우 모두 Dual Learning을 적용했을 때 BLEU score의 비약적인 상승이 있었습니다. 심지어 프랑스어에서 영어로 번역할 때는 low resource로 학습한 dual-NMT가 high-resource로 학습한 NMT와 엎치락 뒤치락하고 있습니다. 위 도표의 pseudo-NMT는 Back-Translation을 적용한 경우인데, 그것보다 최대 4까지 BLEU score가 상승했네요.

newstest2014 데이터에 대해서도, 해당 논문에서 dual learning이 MRT에 기반하여 구현된지라 일반 MRT를 상회하는 성능을 보여줬습니다.
정리
결국 관건은 사람이 문장쌍을 매칭해주지 않고 단방향 코퍼스를 이용하여 얼마나 번역기의 성능을 향상시킬 수 있는가였습니다.
실험 결과를 보면 이 논문에서 제시한 Dual Learning 방법론은 기존의 Single Learning에 비해서 확실한 성능 향상을 보였다고 할 수 있습니다. 다만 아쉬운 것은 MRT에 기반하고 있다는 점입니다. 앞서 우리는 첫 번째 agent에 대해서 Policy gradient를 사용하여 손실을 정의하는 것을 확인했습니다. 이는 샘플링에 기반한 방식이기 때문에 학습 속도가 엄청 느립니다. 게다가 reward가 스칼라로 정의되는 한 gradient descent를 수행할 수도 없습니다.. (스칼라는 방향이 없기 때문입니다)
한 가지 더 아쉬운 점은 Policy Gradient 과정에서 굳이 LM을 사용했다는 것입니다. reward function는 미분이 들어가지 않기 때문에 그냥 BLEU 혹은 GLEU를 reward로 사용했더라면 LM을 따로 훈련하는 번거로움을 피할 수 있지 않았을까 생각해봅니다.
최근에 MRT를 이용한 기계번역기를 훈련시켜보려 했으나, colab pro를 사용하더라도 한 에포크가 무슨 8~10시간이 걸리던 것으로 기억합니다.. 그런데 MRT를 사용하는데다가 모델까지 하나 더 훈련시키자니, 성능 향상은 고사하고 저는 생각도 못해볼 방식인 듯 합니다. 이것보다는 베이즈 정리를 이용하여 Dual loss를 regularization term으로 이용한 방법론이 차라리 효율적인 듯 합니다!



