
while (1): study();
[논문 리뷰] Continual Learning for Natural Language Generation in Task-oriented Dialog Systems 본문
[논문 리뷰] Continual Learning for Natural Language Generation in Task-oriented Dialog Systems
전국민실업화 2022. 1. 8. 20:03링크: https://arxiv.org/abs/2010.00910
Continual Learning for Natural Language Generation in Task-oriented Dialog Systems
Natural language generation (NLG) is an essential component of task-oriented dialog systems. Despite the recent success of neural approaches for NLG, they are typically developed in an offline manner for particular domains. To better fit real-life applicat
arxiv.org
범용 인공지능에 다가가기 위해서 최근 대두되는 주제 중 하나는 continual learning입니다. 다른 말로는 incremental learning, lifelong learning이라고도 합니다. computer vision쪽에서는 이미 많이 활용이 됐으나 nlp쪽에서는 상대적으로 활용이 지금까지 많이 된 느낌은 아닙니다. 이 논문에서는 목적 지향 대화 시스템을 구축하는 데 있어 nlg task를 어떻게 continual learning할지 방법론을 제시합니다.
3. Model
concept-to-text NLG모델의 기본적인 접근 방법은 아래와 같습니다.

d는 dialogue act(담화 행위)로 발화-응답쌍의 집합을 의미합니다. 이는 Intent(혹은 type)와 해당 intent의 slot-value쌍으로 구성됩니다.

모델이 표현하고자 하는 것은 dialogue act와 ground truth가 주어졌을 때 출력 문장의 확률 분포입니다. 이는 연쇄법칙을 이용하여 위와 같이 표현합니다.

loss는 negative log likelihood를 이용하여 각 단어별 교차 엔트로피 손실 평균을 다음과 같이 정의합니다.
여기서 저자들이 제안하는 것은 ARPER(Adaptively Regularized Prioritized Exemplar Replay)입니다. 말 그대로 Exemplar가 dialogue act쌍의 크기에 따라 수를 적응시키며, 가장 우선해야 하는 예제들만을 사용하여 매 태스크마다 모델을 학습시킵니다.
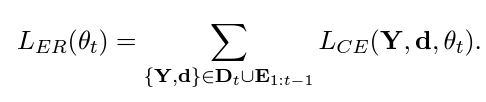
$D_{t}$가 t번째 task의 dialogue act, $E_{1:t-1}$이 이전까지 task에서 구한 exemplar라고 했을 때 위와 같이 두 데이터를 답하여 이에 대해 교차 엔트로피 손실을 구한 것이 Exempar Replay Loss입니다. 이때 Exemplar가 그냥 랜덤하게 추출하는 것이 아니고 다음과 같은 두 가지 기준을 따릅니다.

하나는 대표성으로, 본문에선 priority score라고 합니다. 손실이 낮을수록 우선도가 높으며, 이전에 잘 풀던 문제를 잘 풀었으면 이전 모델을 대표하는 예제로 본다는 뜻입니다. 단, 일반적인 슬롯의 개수가 많은 dialogue act의 경우 상대적으로 손실이 낮아지는 경향이 있으므로 slot의 size를 곱하여 정규화합니다.
또한 다양한 예제를 뽑기 위해서 task의 슬롯이 이미 본 슬롯이면 추가하지 않는 기법도 사용합니다. 전체 알고리즘은 다음과 같이 단순한 반복문을 사용하여 구현됩니다. 이런식으로 exemplar는 m개의 예제를 추출합니다.

앞서 제시한 m이라는 기준은 task의 dialogue act의 개수에 따라서 비율이 달라집니다. dialogue act의 슬롯-밸류쌍이 많아질수록 더 많은 예제를 추출합니다. 대문자 M은 hyperparameter로 본문에선 250, 500을 각각 사용합니다.

다만 모든 이전 데이터를 사용하는 것이 아니라 부분적으로 사용하는 것이기 때문에 정규화의 효과가 약하다고 합니다. 따라서 유명한 정규화 방법인 EWC를 사용합니다. $F_{i}$는 i번째 task의 Fisher Information Matrix인데, 연산상 이점으로 인해 Loss funciton의 Hessian matrix의 근삿값을 사용한다고 볼 수 있습니다. 즉, loss가 빠르게 변화할수록 그리고 파라미터간 차이가 클 수록 손실이 커진다고 볼 수 있으며, 결과적으로 중요한 파라미터의 변화를 최소화합니다. 손실은 최종적으로 아래와 같이 정의할 수 있습니다.

위에 $\lambda$는 각 task의 난이도에 따라 유동적으로 계산합니다. 난이도는 이전까지의 old vocab을 현재 task의 vocab 크기로 나눈 것인데, 현재 task의 vocab이 적다면(난이도가 쉽다면) $\lambda$가 커지게 되고, 이는 EWC 손실의 중요도를 더 크게 만들어 파라미터가 덜 변화하게 만듭니다.

이렇게하여 전체 학습 알고리즘은 아래와 같이 정의됩니다. 위에서 얘기한 내용을 정리한 것에 불과합니다.

4. Experiment
실험에서는 SER(slot per error rate)와 BLUE-4를 사용합니다. 두 지표에 대해 다음과 같이 경우를 나누어 정량적으로 평가합니다. 각각 전체 태스크에 대한 성능과, 첫번째 태스크에 대한 성능을 의미합니다. continual learning이 성공적이려면 두 지표가 모두 좋아야 합니다.

multi-woz2.0 데이터셋에 대해 attraction domain을 먼저 학습시키고, train domain을 이후에 학습시켰을 때 실험 결과는 다음과 같습니다.

Full은 task가 추가될때마다 전체 데이터를 학습한 경우의 성능입니다. 이를 상한선으로 두었을 때 ARPER는 이에 상당히 근접한 성능을 보입니다.
아래는 6개 도메인에 대한 성적입니다.

ARPER가 다른 일반적인 Exemplar Replay에 비해서 좋은 SER을 보여주는 것은 확실합니다. 또한 첫 번째 domain에 대해서는 Full보다 성능이 높기도 합니다. 단, 유효한 예제들을 이용해서 학습시키기 때문에 상대적으로 major한 다수의 태스크에 대해서 좋은 성능을 보이느라 이런 성적이 나온 것은 아닌지 의심해볼 여지가 있습니다.

전체적으로 비교해보자면 ARPER가 심지어 Full에 비해서 좋은 BLEU-4를 보이기도 합니다.
한계
그러나 앞서 언급한 대로 유효한 예제에 대해서만 학습하느라 소수의 예제에 대한 recall이 떨어질 염려가 있습니다. 또한 적응적으로 예제의 수를 감소시킨다고 하더라도 task(domain)의 수만큼 Exemplar가 필요합니다. 이는 도메인 수에 따라 다소 선형적인 연산량 증가를 야기합니다. 마지막으로 Exemplar나 Knowledge Distillation 모두 실제 세계에서는 다음 입력이 꼭 새 task라는 보장이 없기 때문에, 필요에 따라 업데이트 여부를 선택하는 조금 더 효율적인 알고리즘이 없을지 여부가 주목됩니다.



