while (1): study();
[논문 리뷰] A Theoretically Grounded Application of Dropout in Recurrent Neural Networks 본문
[논문 리뷰] A Theoretically Grounded Application of Dropout in Recurrent Neural Networks
전국민실업화 2021. 8. 15. 16:27출처: https://arxiv.org/abs/1512.05287
A Theoretically Grounded Application of Dropout in Recurrent Neural Networks
Recurrent neural networks (RNNs) stand at the forefront of many recent developments in deep learning. Yet a major difficulty with these models is their tendency to overfit, with dropout shown to fail when applied to recurrent layers. Recent results at the
arxiv.org
LSTM-LM의 성능을 개선하기 위해 Variational Dropout에 대해서 찾아보던 도중 발견하게 되었습니다.
1. Introduction
RNN은 익히 알고 있다시피 과적합 문제가 발생하고, 이를 해결하기 위해서 조기종료시키거나, 모델을 작게 만들어 표현력을 제한합니다. 일반적인 드랍아웃의 경우 드랍아웃으로 인한 노이즈가 매 타임스탭마다 누적되어 결과적으로는 부적절한 결과를 도출하게 됩니다. 시간이 지날수록 시간축 신호가 약해지는 문제도 있습니다.
따라서 여기서 제안하는 것은 기존에 RNN 이외의 계층에 드랍아웃을 도입했던 것을, 이제 변형된 드랍아웃을 사용하여 RNN에 직접 드랍아웃을 적용하자는 것입니다. 드랍아웃은 결정적인(Deterministic) 상태를 랜덤성을 도입하여 분포화시키므로 일종의 베이지안 관점에 입각하여 모델링을 수행할 수 있습니다.
추가적으로 단어, 즉 Input 자체를 임베딩하는 방법론도 소개합니다.
2. Background
베이지안 모델은 사후확률의 개념을 파라미터에 도입합니다. 문장을 예로 들면 특정 타임스탭의 정답의 확률분포는 다음과 같이 정리할 수 있습니다.
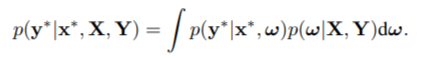
이때 $p(w|X, Y)$는 우리가 구하고자 하는 진리의 가중치 분포입니다. 따라서 이를 사후에 구한 가중치로 근사시켜야 합니다. 두 분포의 유사성을 쿨백-라이블러 발산을 이용하여 측정할 수 있기 때문에, 근사한 분포 $q(w)$와 실제 분포$p(w|X, Y)$ 간의 KL을 최소화하면 됩니다. KL의 정의에 따라서 식을 다음과 같이 근사시킵니다.


따라서 우리의 목표는 위 식을 최소화하는 것이 됩니다. 이를 이용하여 손실함수를 재정의하면 다음과 같습니다.

사실상 기존의 손실함수인 음의 로그 가능도에 KL이 더해진 꼴인데, 실제로 KL은 L2 정규화의 근사식이 된다고 합니다. 따라서 L2 정규화가 적용된 음의 가능도를 손실함수로 사용한다고 볼 수 있겠습니다. 중요한 것은 매 타임스탭마다 w, 즉 가중치 분포가 동일하게 적용되고 있다는 점입니다. 드랍아웃이 결정적인 상태에 확률분포를 도입하므로, 우리는 여기서 매 타임스탭마다 동일한 확률을 부여해야 한다는 사실을 알 수 있습니다.
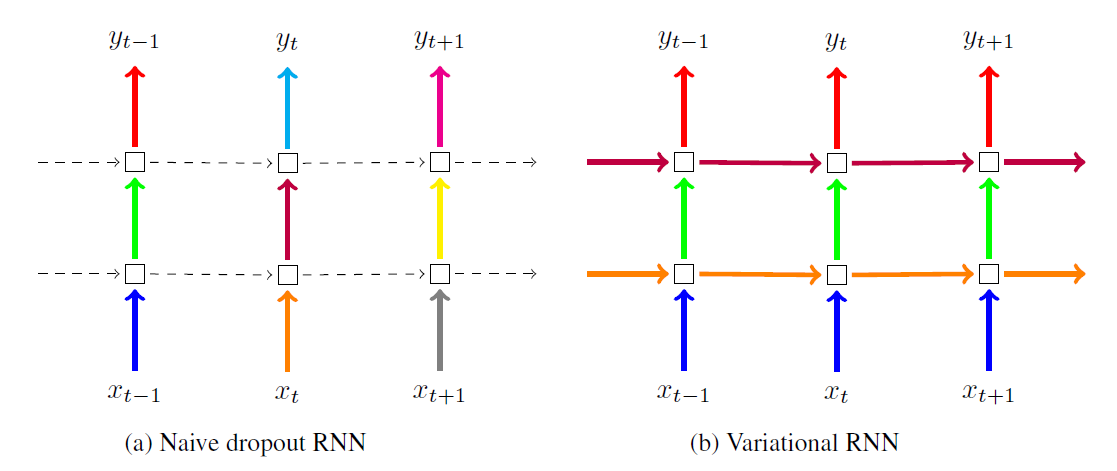
확인해보면 단순히 RNN에 걸친 정보뿐만 아니라 입력과 출력 모두 타임스탭별로 동일한 마스크를 사용합니다.
4.2 Word Embeddings Dropout
사실 RNN 아키텍처에서 가장 크기가 큰 행렬은 바로 임베딩 가중치입니다. 대부분의 경우 단어장의 크기가 다른 하이퍼파라미터보다 비교적 매우 크기 때문입니다. 따라서 임베딩 가중치에서 과적합이 발생할 확률이 농후하나, 실제로 이산적인 특징을 가진 데이터에 대해서는 드랍아웃을 적용하기가 힘듭니다. 여기서는 단어를 원핫벡터 형태로 받고, 특정 타입을 드랍시킵니다. 즉, The cats and the dogs라는 문장에서 _ cats and _ dogs는 가능해도, _ cats and the dogs는 불가능하다는 것입니다. 단, 모든 단어장 수준에서 단어를 샘플링하는 것은 매우 비효율적이기 때문에, 타임스탭의 길이만큼에서 샘플링하여 드랍시키도록 합니다.
5. Experimental Evaluation
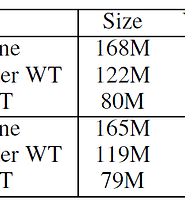
애초에 LM의 성능을 향상시키는 것이 목적이었으므로 LM 부분만 보도록 하겠습니다. Medium 모델의 경우 각 RNN 계층의 노드가 650개이며, Large 모델은 1500개입니다. Medium모델은 Word Embeddings Dropout과 Input, Output Dropout은 0.3, RNN에 걸친 Dropout은 0.25로 주었습니다. Large 모델은 각각 0.6, 0.3입니다.

우선 Medium 모델 자체도 꽤 뛰어난 성능을 보입니다만, Large 모델의 PPL이 큰 폭으로 하락한 게 더욱 인상적입니다. 앞서 거론했다시피 RNN 자체가 과적합이 심한 편이라 과적합을 방지하기 위해서 의도적으로 작은 모델을 만들었고, 큰 모델은 오히려 성능이 저하되는 모습을 보였습니다. 그러나 Variational Dropout을 사용하면 큰 모델에 대해서도 과적합을 효과적으로 억제할 수 있다는 것이 증명된 바입니다.
사실 Word Embeddings Dropout을 사용하지 않고 Variational Dropout만 사용해서 성능을 올려보고 싶은데, 그러다보니 논문과는 최적 파라미터가 꽤 다른 듯 보입니다. 배치 사이즈 20으로 40에포크를 학습하려면 약 6시간 정도 걸리는데, 매번 결과를 확인하기가 쉽지 않기도 하구요. 현재는 조금 큰 배치사이즈로 드랍아웃 확률을 조정해가며 실험해보고 있는데, 좋은 결과가 나왔으면 하는 바램입니다.