
while (1): study();
[논문 리뷰] On Faithfulness and Factuality in Abstractive Summarization 본문
링크: https://arxiv.org/abs/2005.00661
On Faithfulness and Factuality in Abstractive Summarization
It is well known that the standard likelihood training and approximate decoding objectives in neural text generation models lead to less human-like responses for open-ended tasks such as language modeling and story generation. In this paper we have analyze
arxiv.org
Main Question
1. abstractive summarizer에서 얼마나 자주 hallucination이 발생하는가?
70% 이상의 summary에서 발생한다.
2. instrincsic hallucination vs extrinsic hallucination
대부분이 extrinsic. 배경지식을 이용했을수도 있으나 90%는 errorneous
3. hallucination이 얼마나 factual한가? (배경지식의 측면)
pretrained model이 정량평가, 정성평가에서 좋은 성적. 게다가 배경지식을 이용하여 factual hallucination 많음.
4. hallucination을 측정할 metric이 있는가?
ROGUE와 BERTscore는 factuality와 상관계수가 낮고, QA나 entailment 등이 오히려 좋았음.
Hallucination
원인
1. word-level log likelihood는 신뢰성을 보장하지 않는다.
2. 훈련 데이터의 노이즈나 거짓 정보에 대해 무지하다.
most summarization systems are trained to maximize the log-likelihood of the reference summary at the word-level, which does not necessarily reward models for being faithful. Moreover, models are usually agnostic to the noises or artifacts of the training data, such as reference divergence, making them vulnerable to hallucinations
종류
1. Intrinsic hallucination
소스 텍스트의 정보를 이용하여 합성하는 현상. 인코더의 성능이 안 좋을때 혹은 소스 텍스트의 질이 좋지 않을때 발생. 예를 들어 '김 의원은 올해 국회의원 선거에 출마한다.'는 문장에서 '전 국회의원 출신인 김 의원'같은 식으로 다른 의미를 만들어내는 것을 의미.
2. Extrinsic hallucination
소스에 없는 정보가 추가되는 현상. 디코더의 성능이 안 좋을때 혹은 답이 정해져있지 않은 생성 태스크에서 발생. 예를 들어 '김 의원은 국회의원 선거에 출마한다.'는 문장에서 '김 의원은 2016년 국회의원 선거에 출마한다.'같은 식으로 요소를 추가하는 것.
* 항상 errorneous하지 않고, factual hallucination일 수도 있다. (pre-trained model이 학습한 실제 세계의 정보를 활용하는 경우)
Extreme document summarization
Xsum dataset의 BBC 기사에 대해 abstractive summary 진행


BERT-to-BERT가 가장 신뢰할 수 있는 정보를 생성. 뿐만 아니라 factual hallucination의 비율도 BERT2BERT가 가장 높았음. 그러나 여전히 90%의 hallucination이 errorneous함.
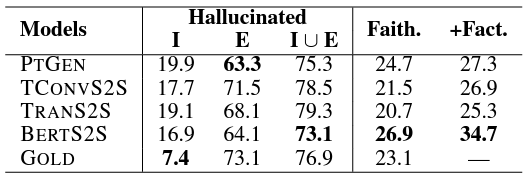
마찬가지로 정성평가에서도 BERT-to-BERT가 가장 hallucination 비율이 적고, 신뢰도가 높았음.
- 앞서 Intrinsic / Extrinsic hallucination이 각각 encoder, decoder의 성능과 연관된다고 했던 것을 고려해보면 GPT의 실패와 BERT2BERT의 성공이 예상이 됨.
- context representation을 만들어내는 NLU 기반 모델의 task가 domain 지식을 충분히 학습하게 만든 것이 아닐까.
Metrics
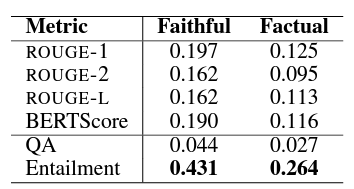
ROGUE나 BERTScore는 스피어만 상관계수에 큰 관계가 없음. BERT-like model을 이용한 Entailment task가 가장 계수가 높음.
Summary
1. abstractive summary에서 hallucination을 다루는 것은 중요하지만 어려운 일이다.
2. NLU 기반 모델이 강세를 보이나, 아직 만족할만한 성능은 아니다.
3. abstractive summary의 평가에 있어 ROGUE나 BERTScore보다 semantic inference based measure(e.g. entailment)가 낫다.



