
목록리뷰 (18)
while (1): study();
 Ch6. 게이트가 추가된 RNN
Ch6. 게이트가 추가된 RNN
이번 장에서는 Vanilla RNN에서 개선된 버전인 LSTM을 구현하여 본격적인 RNN LM을 구축합니다. 기존의 Vanilla RNN은 다음과 같이 계산됩니다. $$h_{t} = tanh(h_{t-1}W_{h} + x_{t}W_{x} + b)$$ 이 때 $W_{h}$와 $W_{X}$는 계층 내에서 같은 가중치이므로, 타임스탭이 길어질 때마다 매번 같은(정확히는 비슷한) 행렬이 입력에 곱해지게 됩니다. 행렬의 최대 특잇값이 1보다 크다면 출력은 지수적으로 증가하고, 1보다 작으면 지수적으로 감소합니다. 따라서 역전파 과정에서 커지거나 작아진 가중치가 곱해지면 기울기도 그에 따라서 폭발하거나 소실될 가능성이 증가합니다. 또한 하이퍼볼릭 탄젠트 함수의 도함수가 0부터 1사이의 값을 가질 수 있기 때문에, ..
 Ch2. 자연어와 단어의 분산 표현
Ch2. 자연어와 단어의 분산 표현
지금까지 자연어 처리에 대해서 공부를 하면서 많은 임베딩 기법들을 접해보았습니다. 최신의 성능좋은 기술에 눈을 돌리다보니 아무래도 그 배경에 대해서는 상대적으로 소홀했던 것 같습니다. 컴퓨터에게 인간의 언어를 이해시키는 방법론은 3가지가 있습니다. 1. 시소러스 방법론 2. 통계 기반 방법론 3. 추론 기반 방법론 이 장에선 위의 반성과 더불어 통계적으로 단어를 분산 표현으로 바꾸는 방법에 대해서 알아봅니다. 1. 시소러스 시소러스의 사전적 정의는 다음과 같습니다. 즉 시소러스 기반 방법론이란, 인간이 구축한 유의어 사전을 기반으로 단어들 간의 연관성을 컴퓨터가 파악하게 하는 것입니다. 대표적인 시소러스로는 프린스턴 대학교에서 1983년부터 구축하기 시작한 WordNet이 있습니다. WordNet은 다음..
 Ch1. 신경망 복습
Ch1. 신경망 복습
대부분의 내용이 반복인 점을 감안하여 새롭게 알게 된 내용을 위주로 작성하겠습니다. 이전 1권에서 곱셈, 덧셈 등 노드에 대해서 어떻게 역전파를 계산하는지 알아봤습니다. 기본적으로 역전파는 '상류에서 흘러들어온 기울기를 편미분'하여 하류로 흘려보냅니다. 여기서는 이전에 제시하지 않았던 종류의 노드를 제시하고 있습니다. 바로 Repeat 노드입니다. Repeat 노드의 순전파는 단순히 들어온 입력을 N번 복사하는 것입니다. 이는 np.repeat 함수로 쉽게 구현이 가능합니다. 반대로 역전파는 흘러들어오는 기울기에 대해서 모두 더해주는 과정입니다. 사실 Repeat 노드는 넘파이의 브로드캐스팅 기능으로 간단히 구현할 수 있기 때문에, 따로 모듈화할 필요는 없습니다. 이전의 기억을 잘 더듬어보면, 덧셈 노드..
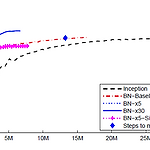 [논문 리뷰] Batch Normalization: Accelerating Deep Network Training by Reducing Internal Covariate Shift
[논문 리뷰] Batch Normalization: Accelerating Deep Network Training by Reducing Internal Covariate Shift
출처: https://arxiv.org/abs/1502.03167 Batch Normalization: Accelerating Deep Network Training by Reducing Internal Covariate Shift Training Deep Neural Networks is complicated by the fact that the distribution of each layer's inputs changes during training, as the parameters of the previous layers change. This slows down the training by requiring lower learning rates and careful param arxiv.org 지..
 Ch7. 합성곱 신경망
Ch7. 합성곱 신경망
이미지 처리의 기반은 CNN 아키텍처이며, CNN 아키텍처는 합성곱 연산을 사용합니다. 이는 필터와 입력 데이터에 대해서 대응하는 위치의 원소끼리 곱한 후 총합을 구하는 것입니다. 이 계산을 단일 곱셈-누산(FMA; Fused Multiply-Add)라고 합니다. 엄밀히 말하면 딥러닝에서의 연산은 교차상관이라고 부르는 것이 맞다고 합니다. 필터를 플리핑(Flipping)하면 합성곱 연산, 그렇지 않으면 교차상관입니다. 하지만 딥러닝에서 그렇게 엄밀히 구분하여 부르는 듯 하지는 않다고 하네요. 합성곱 연산을 수행하면 출력의 크기는 다음과 같이 계산됩니다. H, W는 입력의 높이와 너비, FH, FW는 필터의 높이와 너비, OH, OW는 출력의 높이와 너비, P는 패딩, S는 스트라이드를 의미합니다. $$O..
 Ch5. 오차역전파법
Ch5. 오차역전파법
* 책 내용 요약이 아니니 유의하시기 바랍니다. 오차역전파에 대해서 이전에 해석 강의를 들은 적이 있긴 했는데, 솔직히 감이 잘 안 왔습니다. 이 책을 보고 나서야 비로소 '아! 이런거구나!'라고 제대로 와닿는 느낌이었습니다. 여러모로 읽으면 읽을수록 '읽기를 잘했다'라고 생각이 드는 책이네요. 이 책에서는 계산 그래프를 통해서 오차역전파에 대해 설명하고 있습니다. CS231n에서 설명한 방식을 차용했다고 하는데, 역시 인공지능 배우는 사람이라면 다 한번 거쳐야 하는 관문인걸까.. 싶습니다. 시간 날 때 꼭 봐야겠네요. 계산 그래프로 푸는 방법의 이점은 2가지입니다. 1. 국소적 계산: 단순한 계산에 집중하여 문제를 단순화 2. 중간 계산 결과 보관 3. 미분을 효율적으로 계산 기존 수치 미분 방법을 이..
 Ch4. 신경망 학습
Ch4. 신경망 학습
* 책 내용 요약이 아니니 유의하시기 바랍니다. 신경망 학습 시에 '경사하강법'이라는 용어가 참 많이 나옵니다. 경사하강법이란 '손실함수가 각 가중치에 대해서 양의 기울기를 가지면 음의 방향으로, 음의 기울기를 가지면 양의 방향으로 업데이트시켜 결과적으로는 전역 최소해에 도달하게 만드는 방법'입니다. 일반적으로 다음과 같이 특정 지점의 기울기를 근사할 수 있습니다. 실제 기울기를 해석적으로 구하는 것은 컴퓨터에게 힘든 일이기 때문에, 우리는 수치 미분를 사용할 것입니다. 그중 아래와 같은 방식을 전방 차분이라고 합니다. 다만 전방 차분은 실제 해석적 기울기와는 차이가 좀 있는 편입니다. 따라서 신경망을 학습할 때는 오차를 줄이기 위해 중앙 차분을 사용합니다. 이렇게 구한 기울기는 각 장소에서 함수의 출력..
 Ch3. 신경망
Ch3. 신경망
* 책 내용 요약이 아니니 유의하시기 바랍니다. 1. 소프트맥스 소프트맥스(Softmax) 함수의 지수연산은 값을 Overflow Error를 발생시킬 수 있기 때문에, 다음과 같이 지수가 너무 커지지 않도록 조정해주는 과정이 필요합니다. C라는 임의의 정수가 분모와 분자에 곱해졌을 때, 로그가 취해진 형태로 exp 안에 들어갈 수 있게 됩니다. 이때 logC를 C'라고 표기해봅시다. 즉 우리는 소프트맥스 함수의 분자, 분모의 exp 안에 어떤 수든 더할 수 있다는 것을 알게 되었습니다. 일반적으로 너무 큰 수가 되는 것을 막기 위함이기 때문에, C'는 배열의 최대값에 음수를 취한 값입니다. 이렇게 구한 소프트맥스 확률값 중 가장 큰 인덱스를 정답 라벨로 반환하기 때문에, 사실상 소프트맥스 연산은 출력층..
 Ch2. 퍼셉트론
Ch2. 퍼셉트론
* 책 내용 요약이 아니니 유의하시기 바랍니다. 퍼셉트론은 딥러닝의 근간을 이루고 있는 중요한 아키텍처입니다. 마치 저항이 전류의 흐름을 조절하듯이, 각 노드의 가중치는 신호의 강도를 조절합니다. 이 신호가 임계치(Threshold)를 넘냐 마냐에 따라 퍼셉트론은 0 혹은 1의 값을 출력합니다. 이를 수식으로 표현하면 다음과 같습니다. 퍼셉트론 구조를 통해 주요한 논리연산자 중 AND, NAND, OR 관계를 표현할 수 있습니다. 1. AND 게이트 x1 x2 y 0 0 0 1 0 0 0 1 0 1 1 1 위 진리표를 조건으로 바꾸어보면 다음과 같습니다. 즉 다음 조건을 만족하는 모든 파라미터는 AND 게이트를 구성할 수 있습니다. 2. NAND 게이트 같은 방식으로 진리표를 조건식으로 치환하면 다음과 ..
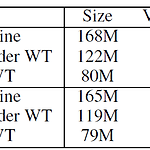 [논문 리뷰] Using the Output Embedding to Improve Language Models
[논문 리뷰] Using the Output Embedding to Improve Language Models
출처: https://arxiv.org/abs/1608.05859 Using the Output Embedding to Improve Language Models We study the topmost weight matrix of neural network language models. We show that this matrix constitutes a valid word embedding. When training language models, we recommend tying the input embedding and this output embedding. We analyze the resulting upd arxiv.org * 하단 포스팅의 후속 포스팅입니다. https://jcy1996.tis..