
목록딥러닝 (22)
while (1): study();
 Ch4. 신경망 학습
Ch4. 신경망 학습
* 책 내용 요약이 아니니 유의하시기 바랍니다. 신경망 학습 시에 '경사하강법'이라는 용어가 참 많이 나옵니다. 경사하강법이란 '손실함수가 각 가중치에 대해서 양의 기울기를 가지면 음의 방향으로, 음의 기울기를 가지면 양의 방향으로 업데이트시켜 결과적으로는 전역 최소해에 도달하게 만드는 방법'입니다. 일반적으로 다음과 같이 특정 지점의 기울기를 근사할 수 있습니다. 실제 기울기를 해석적으로 구하는 것은 컴퓨터에게 힘든 일이기 때문에, 우리는 수치 미분를 사용할 것입니다. 그중 아래와 같은 방식을 전방 차분이라고 합니다. 다만 전방 차분은 실제 해석적 기울기와는 차이가 좀 있는 편입니다. 따라서 신경망을 학습할 때는 오차를 줄이기 위해 중앙 차분을 사용합니다. 이렇게 구한 기울기는 각 장소에서 함수의 출력..
 Ch3. 신경망
Ch3. 신경망
* 책 내용 요약이 아니니 유의하시기 바랍니다. 1. 소프트맥스 소프트맥스(Softmax) 함수의 지수연산은 값을 Overflow Error를 발생시킬 수 있기 때문에, 다음과 같이 지수가 너무 커지지 않도록 조정해주는 과정이 필요합니다. C라는 임의의 정수가 분모와 분자에 곱해졌을 때, 로그가 취해진 형태로 exp 안에 들어갈 수 있게 됩니다. 이때 logC를 C'라고 표기해봅시다. 즉 우리는 소프트맥스 함수의 분자, 분모의 exp 안에 어떤 수든 더할 수 있다는 것을 알게 되었습니다. 일반적으로 너무 큰 수가 되는 것을 막기 위함이기 때문에, C'는 배열의 최대값에 음수를 취한 값입니다. 이렇게 구한 소프트맥스 확률값 중 가장 큰 인덱스를 정답 라벨로 반환하기 때문에, 사실상 소프트맥스 연산은 출력층..
 Ch2. 퍼셉트론
Ch2. 퍼셉트론
* 책 내용 요약이 아니니 유의하시기 바랍니다. 퍼셉트론은 딥러닝의 근간을 이루고 있는 중요한 아키텍처입니다. 마치 저항이 전류의 흐름을 조절하듯이, 각 노드의 가중치는 신호의 강도를 조절합니다. 이 신호가 임계치(Threshold)를 넘냐 마냐에 따라 퍼셉트론은 0 혹은 1의 값을 출력합니다. 이를 수식으로 표현하면 다음과 같습니다. 퍼셉트론 구조를 통해 주요한 논리연산자 중 AND, NAND, OR 관계를 표현할 수 있습니다. 1. AND 게이트 x1 x2 y 0 0 0 1 0 0 0 1 0 1 1 1 위 진리표를 조건으로 바꾸어보면 다음과 같습니다. 즉 다음 조건을 만족하는 모든 파라미터는 AND 게이트를 구성할 수 있습니다. 2. NAND 게이트 같은 방식으로 진리표를 조건식으로 치환하면 다음과 ..
 [논문 리뷰] Using the Output Embedding to Improve Language Models
[논문 리뷰] Using the Output Embedding to Improve Language Models
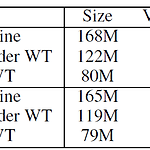
출처: https://arxiv.org/abs/1608.05859 Using the Output Embedding to Improve Language Models We study the topmost weight matrix of neural network language models. We show that this matrix constitutes a valid word embedding. When training language models, we recommend tying the input embedding and this output embedding. We analyze the resulting upd arxiv.org * 하단 포스팅의 후속 포스팅입니다. https://jcy1996.tis..
 [논문 리뷰] The University of Edinburgh's Neural MT Systems for WMT17
[논문 리뷰] The University of Edinburgh's Neural MT Systems for WMT17
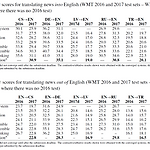
출처: https://aclanthology.org/W17-4739/ The University of Edinburgh’s Neural MT Systems for WMT17 Rico Sennrich, Alexandra Birch, Anna Currey, Ulrich Germann, Barry Haddow, Kenneth Heafield, Antonio Valerio Miceli Barone, Philip Williams. Proceedings of the Second Conference on Machine Translation. 2017. aclanthology.org BT(Back Translation)과 BPE(Byte Pair Encoding)로 유명한 Rico Sennrich 교수팀이 WMT17에..
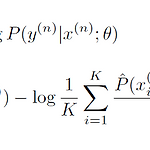 [논문 리뷰] Dual Transfer Learning for Neural Machine Translation with Marginal Distribution Regularization
[논문 리뷰] Dual Transfer Learning for Neural Machine Translation with Marginal Distribution Regularization
출처: https://dblp.org/rec/conf/aaai/WangXZBQLL18.html dblp: Dual Transfer Learning for Neural Machine Translation with Marginal Distribution Regularization. For web page which are no longer available, try to retrieve content from the of the Internet Archive (if available). load content from web.archive.org Privacy notice: By enabling the option above, your browser will contact the API of web.arch..
 [논문 리뷰] Dual Learning for Machine Translation
[논문 리뷰] Dual Learning for Machine Translation
출처: https://arxiv.org/abs/1611.00179 Dual Learning for Machine Translation While neural machine translation (NMT) is making good progress in the past two years, tens of millions of bilingual sentence pairs are needed for its training. However, human labeling is very costly. To tackle this training data bottleneck, we develop a du arxiv.org 이번에 기계 번역기 구현 다 마치고, colab 환경에서 dual learning을 이용한 fine-..
 [논문 리뷰] On Layer Normalization in the Transformer Architecture
[논문 리뷰] On Layer Normalization in the Transformer Architecture
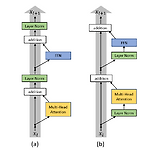
출처: https://arxiv.org/abs/2002.04745 On Layer Normalization in the Transformer Architecture The Transformer is widely used in natural language processing tasks. To train a Transformer however, one usually needs a carefully designed learning rate warm-up stage, which is shown to be crucial to the final performance but will slow down the optimizati arxiv.org 1. Introduction Transformer는 현재 자연어처리 외..
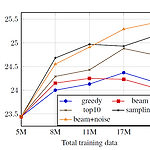 [논문 리뷰] Understanding Back-Translation at Scale
[논문 리뷰] Understanding Back-Translation at Scale
출처: https://arxiv.org/abs/1808.09381 Understanding Back-Translation at Scale An effective method to improve neural machine translation with monolingual data is to augment the parallel training corpus with back-translations of target language sentences. This work broadens the understanding of back-translation and investigates a numb arxiv.org 페이스북과 구글의 공동연구로 2018년 발표한 글입니다. 1. Introduction 기계번역기를..
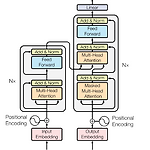 [논문 리뷰] Attention is All You Need
[논문 리뷰] Attention is All You Need
출처 : https://arxiv.org/abs/1706.03762 Attention Is All You Need The dominant sequence transduction models are based on complex recurrent or convolutional neural networks in an encoder-decoder configuration. The best performing models also connect the encoder and decoder through an attention mechanism. We propose a new arxiv.org 구글 연구팀에서 2017년 발표한 논문입니다. 구글의 기존 Seq2Seq 모델에 대응한 '페이스북의 ConvS2S'가 발표..