
목록전체 글 (116)
while (1): study();
 [논문 리뷰] CatBoost: unbiased boosting with categorical features
[논문 리뷰] CatBoost: unbiased boosting with categorical features
출처: https://arxiv.org/abs/1706.09516 CatBoost: unbiased boosting with categorical features This paper presents the key algorithmic techniques behind CatBoost, a new gradient boosting toolkit. Their combination leads to CatBoost outperforming other publicly available boosting implementations in terms of quality on a variety of datasets. Two criti arxiv.org 사실 이번에 개인적으로 진행하고 있는 대회에서 CatBoost를 상당히 ..
 [백준/1932] 정수 삼각형
[백준/1932] 정수 삼각형
출처: https://www.acmicpc.net/problem/1932 1932번: 정수 삼각형 첫째 줄에 삼각형의 크기 n(1 ≤ n ≤ 500)이 주어지고, 둘째 줄부터 n+1번째 줄까지 정수 삼각형이 주어진다. www.acmicpc.net 간단한 다이나믹 프로그래밍 문제입니다. 전체 소스코드는 다음과 같습니다. n = int(input()) tmp = [] for _ in range(n): tmp.append(list(map(int, input().split()))) array = [[0] * (n + 1)] for item in tmp: if len(item) < n: item += [0] * (n - len(item)) array.append([0] + item) table = [[0] * (..
 [Flipkart 인터뷰] 금광
[Flipkart 인터뷰] 금광
n x m 크기의 금광이 있습니다. 금광은 1 x 1 크기의 칸으로 나누어져 있으며, 각 칸은 특정한 크기의 금이 들어 있습니다. 채굴자는 첫 번째 열부터 출발하여 금을 캐기 시작합니다. 맨 처음에는 첫 번째 어느 행에서든 출발할 수 있습니다. 이후에 m번에 걸쳐서 매번 오른쪽 위, 오른쪽, 오른쪽 아래 3가지 중 하나의 위치로 이동해야 합니다. 결과적으로 채굴자가 얻을 수 있는 금의 최대 크기를 촐력하는 프로그램을 작성하세요. 입력 조건 - 첫째 줄에 테스트 케이스 T가 입력됩니다. (T는 1 이상 1000 이하) - 매 테스트 케이스 첫째 줄에 n과 m이 공백으로 구분되어 입력됩니다. (n, m은 1 이상 20 이하), 둘째 줄에 n x m개의 위치에 매장된 금의 개수가 공백으로 구분되어 입력됩니다...
 [2020 카카오 신입 공채 1차] 가사 검색
[2020 카카오 신입 공채 1차] 가사 검색
출처: https://programmers.co.kr/learn/courses/30/lessons/60060 코딩테스트 연습 - 가사 검색 programmers.co.kr 풀이1 문자열을 다루는 문제를 유독 많이 출제하는 카카오이지만 문자열 이진탐색은 덕분에 처음 접해본 듯 합니다. 처음에 접근했던 코드는 다음과 같습니다. def solution(words, queries): import re array = [] for q in queries: length = len(q) pos = 'pre' if q[-1] == '?' else 'post' keyword = re.sub('\?', '', q) cnt = 0 tmp_words = sorted([w for w in words if len(w) == len..
 [백준/2110] 공유기 설치
[백준/2110] 공유기 설치
출처: 2110번: 공유기 설치 (acmicpc.net) 2110번: 공유기 설치 첫째 줄에 집의 개수 N (2 ≤ N ≤ 200,000)과 공유기의 개수 C (2 ≤ C ≤ N)이 하나 이상의 빈 칸을 사이에 두고 주어진다. 둘째 줄부터 N개의 줄에는 집의 좌표를 나타내는 xi (0 ≤ xi ≤ 1,000,000,000)가 www.acmicpc.net 아이디어를 떠올리기 쉽지 않은 이진탐색 문제이다. 공유기 간 최소거리를 정해놓고 몇 개의 공유기가 설치될 수 있는지 확인한다. 설치할 수 있는 공유기의 개수를 기준삼아 설치해야 하는 공유기의 개수보다 적으면 최소거리를 적게 잡는다. 반대의 경우엔 이미 설치해야 하는 만큼 설치가 가능하다는 의미이므로 정답을 저장하되, 최대거리를 구하는 문제이므로 더 큰 거..
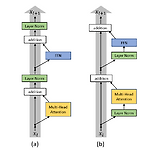 [논문 리뷰] On Layer Normalization in the Transformer Architecture
[논문 리뷰] On Layer Normalization in the Transformer Architecture
출처: https://arxiv.org/abs/2002.04745 On Layer Normalization in the Transformer Architecture The Transformer is widely used in natural language processing tasks. To train a Transformer however, one usually needs a carefully designed learning rate warm-up stage, which is shown to be crucial to the final performance but will slow down the optimizati arxiv.org 1. Introduction Transformer는 현재 자연어처리 외..
 [Amazon 인터뷰] 고정점 찾기
[Amazon 인터뷰] 고정점 찾기
문제 보기 ↓ 더보기 고정점이란, 수열의 원소 중에서 그 값이 인덱스와 동일한 원소를 의미합니다. 예를 들어 수열 a = {-15, -4, 2, 8, 13}이 있을 때, a[2] = 2이므로, 고정점은 2가 됩니다. 하나의 수열이 N개의 서로 다른 원소를 포함하고 있으며, 모든 원소가 오름차순으로 정렬되어 있습니다. 이때 이 수열에서 고정점이 있다면, 고정점을 출력하는 프로그램을 작성하세요. 고정점은 최대 1개만 존재합니다. 만약 고정점이 없다면 -1을 출력합니다. 단, 이 문제는 시간 복잡도 O(logN)으로 알고리즘ㅇ르 설계하지 않으면 '시간 초과' 판정을 받습니다. 입력 조건 첫째 줄에 N이 입력됩니다. (1
 [백준/1715] 카드 정렬하기
[백준/1715] 카드 정렬하기
출처: 1715번: 카드 정렬하기 (acmicpc.net) 1715번: 카드 정렬하기 정렬된 두 묶음의 숫자 카드가 있다고 하자. 각 묶음의 카드의 수를 A, B라 하면 보통 두 묶음을 합쳐서 하나로 만드는 데에는 A+B 번의 비교를 해야 한다. 이를테면, 20장의 숫자 카드 묶음과 30장 www.acmicpc.net 전형적인 그리디 유형의 문제입니다. 대략적인 점화식을 써보자면 sum_n = a_n + sum_n-1과 같습니다. 즉 이전까지의 카드 뭉치의 합은 계속 더해지므로 가장 작은 카드 뭉치들을 먼저 합쳐나가는 방식으로 풀어나가면 됩니다. 다만 주의할 점은 단순한 정렬과 반복으로는 풀 수 없다는 점입니다. 다음 코드를 살펴봅시다. n = int(input()) array = [] for _ in ..
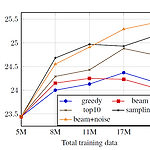 [논문 리뷰] Understanding Back-Translation at Scale
[논문 리뷰] Understanding Back-Translation at Scale
출처: https://arxiv.org/abs/1808.09381 Understanding Back-Translation at Scale An effective method to improve neural machine translation with monolingual data is to augment the parallel training corpus with back-translations of target language sentences. This work broadens the understanding of back-translation and investigates a numb arxiv.org 페이스북과 구글의 공동연구로 2018년 발표한 글입니다. 1. Introduction 기계번역기를..
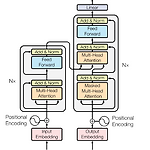 [논문 리뷰] Attention is All You Need
[논문 리뷰] Attention is All You Need
출처 : https://arxiv.org/abs/1706.03762 Attention Is All You Need The dominant sequence transduction models are based on complex recurrent or convolutional neural networks in an encoder-decoder configuration. The best performing models also connect the encoder and decoder through an attention mechanism. We propose a new arxiv.org 구글 연구팀에서 2017년 발표한 논문입니다. 구글의 기존 Seq2Seq 모델에 대응한 '페이스북의 ConvS2S'가 발표..